Every manufacturing company is being told to move faster, automate more, and find new ways to use AI. And honestly, that makes sense. The potential is real. AI can help teams reduce downtime, improve quality, catch issues earlier, and make better decisions across operations. But there is one problem that shows up again and again. A lot of companies want AI outcomes before they have the data foundation to support them.
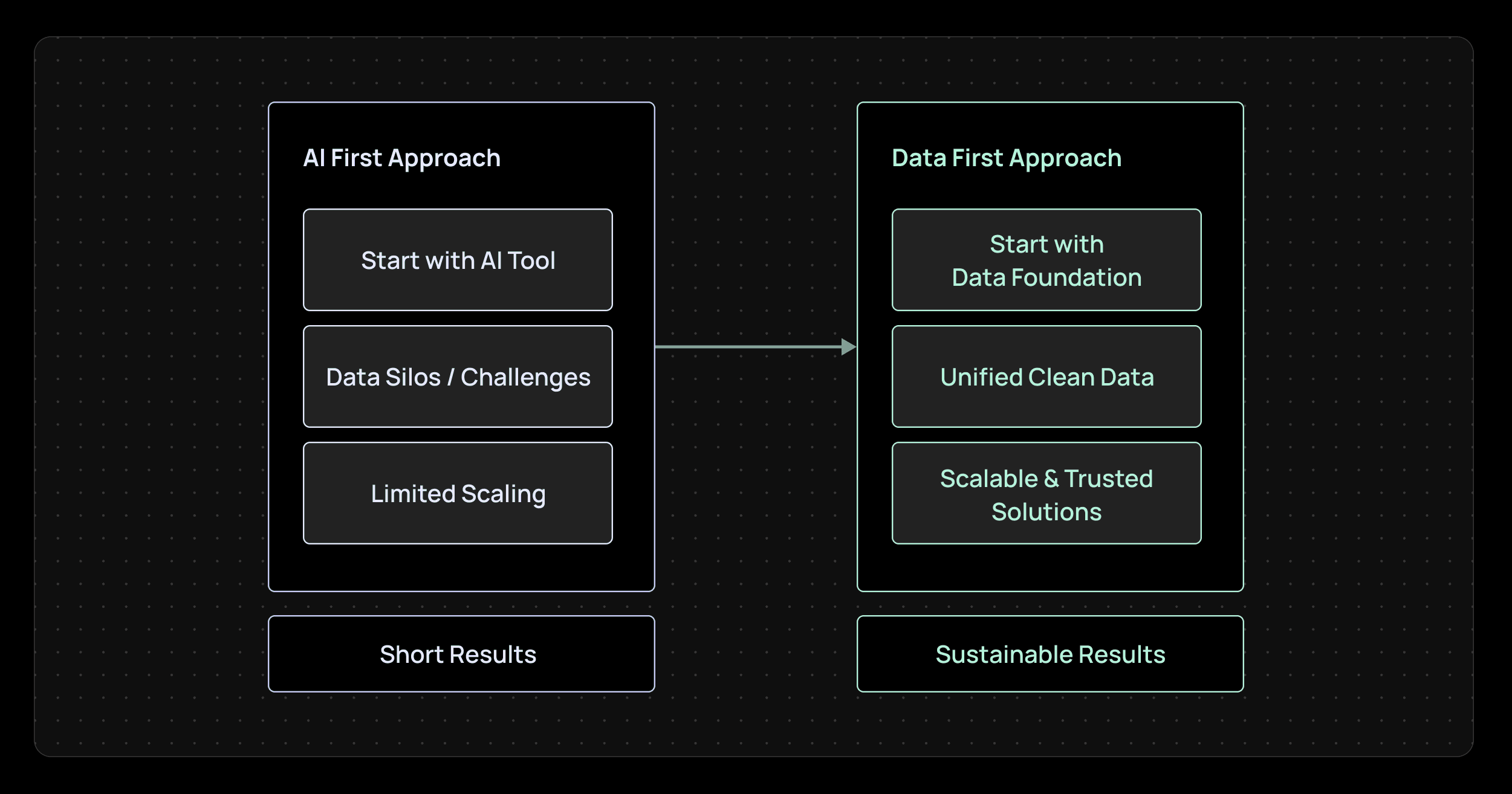
That is where the difference between an AI-first approach and a data-first approach really matters.
At Litmus, we believe AI can create real value in manufacturing, but only when it is built on the right data foundation. If your industrial data is disconnected, inconsistent, delayed, or missing context, AI will only take you so far. You may get a pilot working. You may even get a few interesting results. But scaling that success across lines, plants, and teams becomes much harder than it should be. That is why, from our point of view, the path to successful AI is not AI-first. It is data-first.
It is easy to get excited about AI. New models, copilots, automation tools, and intelligent applications are launching all the time. For many leaders, the pressure is not whether to adopt AI—it is how quickly they can get started. But in industrial environments, AI is not just a software decision. It depends on the quality of the data coming from machines, systems, sites, and operations. And that data is often spread across PLCs, SCADA, historians, MES, ERP systems, cloud platforms, and local databases. So the real question is not just “How do we use AI?”, the better question is “Do we have the right data foundation to make AI actually work?”
An AI-first approach starts with the outcome everyone wants to see: AI in action.
Usually, it sounds something like this:
Let’s launch an AI initiative this quarter
Let’s test a copilot for operations
Let’s build predictive models for maintenance
Let’s use AI for operator assistance
There is nothing wrong with ambition. The issue is what happens when AI is introduced before the data is ready. In many industrial environments, data is still fragmented. Different plants use different naming structures. Different teams define metrics differently. Some data is real time, some is not. Some data has context, and some is just raw machine signals with no clear meaning around it.
So when companies take an AI-first route, they often run into the same wall: the AI idea is strong, but the data underneath it is messy.
That usually leads to:
Slow deployment
Heavy integration work
Inconsistent results
Low trust from operations teams
Pilots that never really scale
A data-first approach starts one step earlier. Instead of asking, “Where can we use AI?” it asks “How do we make our industrial data usable, trusted, and scalable so AI can deliver real value?”
A data-first strategy focuses on building the conditions that AI needs in order to succeed:
Connecting data from machines and systems
Making that data available in real time
Standardizing it across lines, assets, and sites
Adding context so the data actually means something
Creating governance, consistency, and trust
Making the data usable across analytics, applications, and AI
Dimension | Data-First | AI-First |
Primary focus | Data integration, quality, and governance | Rapid AI adoption and tool experimentation |
Typical steps | Collect → Clean → Unify → Govern → Apply AI | Select model → Integrate → Tune data as needed |
Outcome | Reliable, scale-ready AI with proven ROI | Fast proof-of-concepts, higher rework risk |
Risk profile | Lower operational and compliance risk | Higher chance of model drift, bias, and data gaps |
In manufacturing, things are rarely simple. You are working across different vendors, legacy equipment, site-specific setups, OT and IT teams, and systems that were never designed to work together out of the box. That is exactly why a data-first approach matters so much. It helps solve the practical issues that usually hold AI back.
A temperature reading, pressure tag, or machine event only tells part of the story. To be useful for AI, that data needs context:
Which asset did it come from?
Which line or process does it belong to?
Was the machine running normally at that time?
What product or batch was being produced?
Does this signal relate to quality, downtime, or performance?
Without that context, AI is working with fragments. A data-first approach helps turn those fragments into something complete and usable.
A pilot can survive on a small, hand-prepared data set. Once you try to roll the same AI initiative across multiple plants or production lines, the cracks start to show. Every site may have different machines, different tags, different structures, and different ways of working. If you do not have a strong data foundation, every new AI project becomes another integration project. That is expensive and slow. And it makes scale much harder than it needs to be. A data-first approach helps create reusable data models and pipelines, which means new AI use cases do not have to start from scratch every time.
People on the plant floor are not going to trust AI just because leadership wants it. They will trust it when the data behind it is accurate, timely, and clearly tied to real operations. If the inputs are inconsistent, the outputs will always be questioned. A data-first approach helps create that trust because the data is more structured, more transparent, and easier to validate.
This is another big advantage. When you build a strong industrial data foundation, you are not only preparing for AI. You are also making it easier to support:
Dashboards and reporting
Production monitoring
Root cause analysis
Quality improvement
Energy optimization
Predictive maintenance
Cross-site visibility
Better decision-making overall
That is why data-first is such a smart move. It supports AI, but it also delivers value beyond AI.
At Litmus, this is exactly how we think about Industrial AI. We do not see AI as something that sits off to the side, disconnected from operations. We see it as something that depends on strong industrial data from the start. That means helping manufacturers:
Connect data from any machine or industrial system
Collect and use data closer to the source
Add structure and context to that data
Make it available across systems and teams
Build a scalable foundation for analytics, applications, and AI
This is where a data-first approach becomes practical. It is not just a strategy discussion. It is how manufacturers create the conditions for AI to work in the real world.
AI-first often feels faster because it gets people moving quickly. It creates momentum. It gives teams something exciting to test. But data-first is what helps that momentum last.
It gives companies a way to move from:
pilot to production
one site to many sites
one use case to many use cases
isolated success to repeatable success
AI absolutely has a role to play in the future of manufacturing. But the companies that get the most value from it will not be the ones that rush in first. They will be the ones that prepare best. That preparation starts with data. Connected data. Contextualized data. Trusted data. Scalable data. At Litmus, we believe that when manufacturers take a data-first approach, AI becomes far more useful, far more practical, and far more likely to deliver measurable results.
AI-first starts with AI tools. Data-first starts by building a strong data foundation so AI can work reliably and scale more easily.
Because manufacturing data is often spread across many systems and sites. A data-first approach helps make that data usable, consistent, and trusted before AI is applied.
It can work in small pilots, but scaling it across operations becomes much harder. Without a strong data foundation, AI projects often become slower, more expensive, and harder to trust.
Litmus helps manufacturers connect, contextualize, and operationalize industrial data so it can support analytics, applications, and AI at scale.