
Industrial AI is creating demand for a new generation of applications at the edge. Historians store production data. SCADA dashboards show real-time status. Analytics engines calculate OEE and quality metrics. ML models identify anomalies before they become downtime. But deploying applications is rarely the challenge. Deploying them consistently across plants, connecting them to operational data, and managing them at scale is where most organizations struggle.
Plant floors run on software. Yet many manufacturers still rely on fragmented deployment processes, disconnected infrastructure, and manual updates to keep critical applications operational. Litmus Edge addresses this directly. Its built-in application hosting capability lets you deploy, manage, and run containerized applications right where data is generated—at the edge, inside the plant, or across distributed operations—without building a separate infrastructure layer to support it.
Litmus Edge application hosting is the ability to deploy and run software applications on an industrial edge— a compute node positioned close to the machines and processes it supports. Rather than routing all workloads to a centralized hosting or cloud environment, edge application hosting lets specific applications run locally, operating directly against real-time OT data with no round-trip latency.
In the Litmus Edge context, this means running Docker-based containerized applications on the same platform that connects your devices, contextualizes your data, and manages your integrations. It's one platform, not four.
For manufacturers pursuing Industrial AI, edge application hosting is becoming increasingly important. AI inference engines, analytics platforms, digital twins, and operational intelligence applications all depend on timely access to production data. Running these workloads at the edge reduces latency, minimizes bandwidth requirements, and enables applications to continue operating even when cloud connectivity is unavailable.
The challenge is ensuring those applications have access to trusted, contextualized industrial data—not just raw machine signals. That's where an industrial data foundation becomes critical.
Most manufacturers don't have an application problem. They have a coordination problem. Across plants, organizations often accumulate dozens of databases, dashboards, analytics tools, custom scripts, and AI applications over time. Individually, these tools can deliver value. Collectively, they can become difficult to govern, update, scale, and integrate with operational data sources.
When a new analytics tool needs to go live at five sites, someone has to physically access each location, configure the deployment, and wire it into local data sources. When an app update ships, that process repeats. When something breaks, there's no centralized log to check. Multiply this across a fleet of 20, 50, or 200 edge devices across different facilities, and the operational overhead becomes a real drag on your teams.
Litmus Edge changes this by treating application hosting as a first-class capability of the industrial edge platform—not an afterthought bolted on later.
Litmus Edge hosts applications as Docker containers, running in isolated runtime environments directly on the edge device. Each application operates independently — it can't interfere with other containers or with the core Litmus Edge platform. This isolation also supports multi-tenancy, where different teams or use cases can run separate applications on the same edge system.
The Applications module in Litmus Edge organizes everything you need in one place:
Catalogs — your registered public and private application repositories
Containers — a live view of all running, paused, and stopped application instances
Images — Docker images pulled to the device, with disk usage tracking
Volumes — persistent storage mounted to applications
Networks — network configurations available to hosted containers
This gives plant automation engineers and OT architects a single pane of glass for understanding what's running, where, and in what state — without needing to SSH into individual machines or check multiple tools.
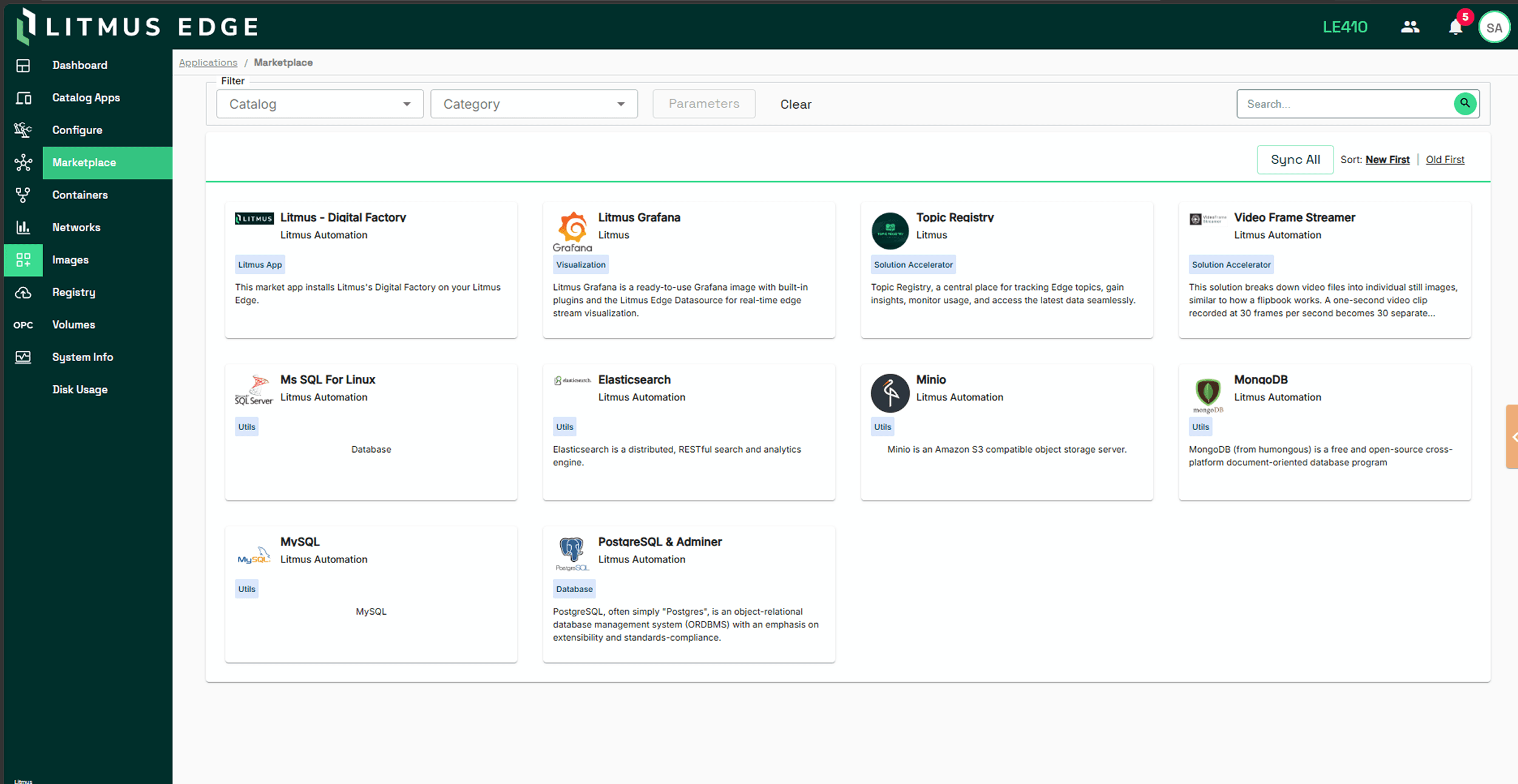
Every Litmus Edge instance includes access to a default public marketplace with a curated set of ready-to-deploy applications. These include databases, search engines, time-series stores, and runtimes commonly used in industrial and data engineering contexts:
Elasticsearch — distributed search and analytics engine
MongoDB — document-oriented database for operational data
MySQL / PostgreSQL / PipelineDB — relational database options for structured process data
MinIO — S3-compatible object storage, commonly used in air-gapped environments
KX (kdb+) — high-performance in-memory time-series database built for real-time and historical data
Python — runtime environment for custom scripts, data processing, and ML inference
Beyond the public marketplace, you can register private marketplace repositories — custom Docker-based applications developed by your organization, an OEM partner, or a systems integrator. This private marketplace is particularly important for organizations operating on private networks or in air-gapped facilities where no external internet connectivity is available. Once an application image is pulled and installed, subsequent instances can be launched without any internet access.
This means the same custom analytics app, the same SCADA historian bridge, or the same ML inference container can be standardized once and deployed consistently across the sites.
Hosting applications at the edge is valuable. But application hosting alone doesn't solve the underlying challenge of Industrial AI readiness. Applications require access to connected, normalized, contextualized, and governed industrial data. Without that foundation, organizations often find themselves building custom integrations, maintaining duplicate data pipelines, or spending significant effort preparing data before applications can use it.
This is why Litmus combines application hosting with the core capabilities of an Industrial Data Foundation—including data connectivity, Industrial DataOps, edge intelligence, data security and governance, and centralized management.
What makes application hosting in Litmus Edge more than just a container runtime is its tight integration with the rest of the platform. Data collected and normalized through Litmus Edge DeviceHub— from PLCs, SCADA systems, historians, sensors, and other OT assets — is available to hosted applications without building a separate data pipeline.
Once raw signals are collected and normalized into a standard format, that contextualized data becomes accessible to any application running on the same edge instance. A hosted PostgreSQL database can store it. A hosted analytics app can process it. A custom ML container can run inference against it. And a data integration connector can forward the results to your cloud or enterprise systems.
The result is a tightly integrated data loop—from device to edge app to enterprise—all running locally, with no dependency on cloud connectivity for the core workflow.
Running third-party or custom applications on industrial infrastructure carries real security obligations. Litmus Edge addresses this through several mechanisms:
Container isolation: each application runs in its own Docker container, preventing cross-application interference and limiting blast radius if an issue occurs
Private marketplace access control: private repositories can be set up with authentication, restricting which devices or users can pull and deploy from them
Air-gapped support: private catalogs work on networks with no internet access, keeping sensitive environments closed
RBAC and authentication: role-based access control, HTTPS, LDAP, and Active Directory integration govern who can deploy or modify applications
Certificate management: secures communications between containers and external systems
For OT engineers who've spent years guarding plant networks from unauthorized access, these controls matter.
Deploying an application on a single edge device is relatively straightforward. Scaling that same application across dozens of facilities while maintaining version control, security, governance, and operational consistency is a very different challenge.
As Industrial AI initiatives expand beyond pilot projects, centralized application management becomes essential. Organizations need a way to deploy applications consistently, monitor them remotely, and govern updates across an entire fleet of edge infrastructure. That's where Litmus Edge Manager comes in. Litmus Edge Manager acts as the single point of control for all Litmus Edge instances across your organization. For application hosting specifically, it provides:
Litmus Edge Manager includes a Marketplace Catalog that lets you organize, version, and distribute applications across your entire fleet. You create a primary catalog at a central location—containing the approved application images your organization wants to standardize—and edge sites pull from it through secondary catalogs that sync with the primary.
When you release a new version of an analytics app, you publish it to the primary catalog once. All connected secondary catalogs receive the update, and you can deploy it to any subset of edge devices in a few clicks. Sites in air-gapped or restricted networks can still receive updates through the catalog sync mechanism, without requiring direct internet access at the site level.
From Litmus Edge Manager, you can start, stop, update, and remove applications across any device in your fleet — without touching individual edge nodes. You can filter by device group, target specific sites, and monitor deployment status from a single interface.
The Application Details pane gives you per-device visibility: which version is running, current container state, and live application logs. For operations teams supporting distributed plants, this replaces hours of remote troubleshooting with a direct, centralized view.
Litmus Edge Manager supports Over-the-Air (OTA) software updates for applications — meaning you can push new container images to edge devices remotely, on a schedule or immediately, without physical site access. This is critical for organizations maintaining software consistency across dozens of facilities where sending a technician on-site for each update is neither practical nor cost-effective.
Litmus Edge Manager includes a secure private Docker registry — a controlled repository for your organization's container images. IT teams manage image access and authentication centrally, ensuring that only approved, vetted application images can be deployed to edge devices across the fleet. This closes a significant governance gap that arises when edge deployments are managed ad hoc without a central image store.
Together, these capabilities mean that application hosting in Litmus Edge isn't just a per-site feature—it's a scalable, manageable, enterprise-grade capability that grows with your deployment.
Consider a mid-sized manufacturer with 12 production sites. Each site runs Litmus Edge for device connectivity and data contextualization. The central IT/OT team wants to standardize a PostgreSQL database and a custom OEE analytics container across all sites. They publish both applications to the primary catalog in Litmus Edge Manager. Each site's secondary catalog syncs automatically. The team deploys both containers to all 12 edge devices from a single interface — no travel, no per-site configuration scripts. Three months later, the analytics container is updated. The new image is published to the primary catalog, and the team pushes the update to all devices in a single OTA deployment. Application logs are accessible centrally for any device showing issues.
The OT data flowing through DeviceHub on each device feeds directly into both the local database and the analytics container. Nothing leaves the plant unless it needs to.
Industrial organizations are deploying more software at the edge than ever before—from historians and analytics platforms to AI inference engines and operational intelligence applications. The challenge isn't simply running these applications. It's deploying, managing, and scaling them consistently across sites while ensuring they have access to trusted operational data.
Litmus Edge combines application hosting, industrial connectivity, data operations, and centralized management in a single platform. The result is an Industrial Data Foundation that enables manufacturers to operationalize applications faster, simplify edge infrastructure, and scale Industrial AI initiatives with confidence.
See how Litmus Edge handles application hosting in your environment—from first deployment to fleet-scale management.
See how Litmus Edge handles application hosting in your environment—from first deployment to fleet-scale management. Try it for Free →
Explore the full Applications documentation at docs.litmus.io.
Litmus Edge supports any Docker-based containerized application. The default public marketplace includes databases (PostgreSQL, MySQL, MongoDB), search engines (Elasticsearch), time-series stores (KX/kdb+), object storage (MinIO), and Python runtimes. You can also add private marketplace catalogs with custom or OEM-built applications.
Litmus Edge Manager provides a centralized Marketplace Catalog where you publish application images once and deploy them to any number of edge devices across your fleet. It supports OTA updates, application lifecycle management (start, stop, update, remove), and a secure private Docker registry — all from a single interface, without requiring on-site access.
Each application runs in an isolated Docker container, preventing interference with other apps or the core Litmus Edge platform. Additional controls include private marketplace authentication, RBAC, HTTPS, LDAP and Active Directory integration, and certificate management — designed for environments where network security is non-negotiable.
Applications hosted on Litmus Edge have direct access to data normalized and contextualized through DeviceHub. Once raw signals from PLCs, historians, sensors, and other OT assets are collected and standardized, that data is available to any application running on the same edge instance — no separate data pipeline required.