
Your cloud analytics platform receives a tag named L3_Machine2 with a value of 14.7. No unit. No asset name. No location. No relationship to the line it runs on or the shift it belongs to. Just a number.
Someone on your data engineering team now spends hours mapping that tag back to a CNC machine in Toronto, on Line 1, running at 14.7 kW during the night shift. Multiply this by thousands of tags across dozens of sites, and you have a data quality problem that no cloud transformation layer can fix after the fact.
The answer isn't faster pipelines. It's a model-first approach—building a Data Model at the edge, before data leaves the source.
In Litmus Edge, Data Models are called Digital Twins—and the two terms refer to exactly the same thing in the platform's technical language. A Digital Twin is a virtual representation of a physical industrial asset, process, or use case. It stores both the identity metadata of that asset (static attributes) and its real-time operational data (dynamic attributes) in a single, structured object.
Every Digital Twin in Litmus Edge is built from a model—a reusable template—and any number of instances derived from that model. A model for a CNC machine gets deployed once; instances represent the specific CNC machines at each plant site. The model defines the structure. The instances carry the live data.
This is the foundation of the model-first approach: you define the data structure at the edge, where the data originates, and every downstream receiver—cloud, historian, analytics platform, Unified Namespace—gets a structured, context-rich payload, not a stream of tag values.
For years, the default approach to industrial data integration was straightforward: collect raw tags from PLCs and historians, push them upstream over OPC-UA or MQTT, and let cloud-side ETL pipelines sort out the meaning. This worked—barely—when the number of data consumers was small and tag volumes were manageable.
That model breaks under the weight of modern Industrial AI and analytics requirements. Cloud-side transformation is expensive, slow, and fragile. Every time an asset is reconfigured or a tag name changes at the source, downstream mappings break. Data quality degrades silently. Analytics teams spend the majority of their time on data preparation, not analysis.
The deeper issue is architectural: context added after data leaves the edge is always a reconstruction. You're inferring what the data meant, not preserving what it was.
Litmus Edge gives you four building blocks to define a complete Data Model.
Static Attributes — The Identity Layer
Static attributes are the metadata that describe the asset: manufacturer, serial, model, plant, line, location. They don't change between data publications—they identify the asset that produced the data. When you create instances from the model, you fill in the actual values for each physical asset. One model, many instances, each with its own static identity.
Dynamic Attributes — The Real-Time Data Layer
Dynamic attributes are the live operational signals: temperature, vibration, power, energyUsed, downtime, cost. Each dynamic attribute maps to a data topic on Litmus Edge's internal message broker. You define the attribute name, unit, and data type in the model. In each instance, you point that attribute at the specific topic where the live tag data is published.
Transformations — Turning Raw JSON Into Structured Payloads
This is where Litmus Edge goes beyond simple tag forwarding. Transformations convert the raw JSON published on device topics into a defined output format. You can write JSON path transformations to extract and rename specific fields, or use JSONata for computed outputs. For example, calculating cost from energyUsed and energyRate, or generating a season label from a timestamp value.
A more advanced JSONata transformation can compute derived values inline, without requiring a separate analytics step downstream:
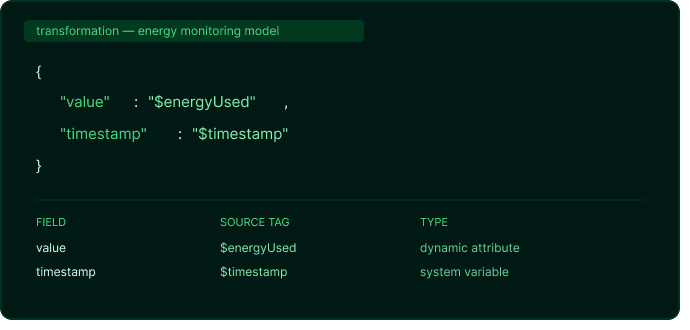
A simple transformation for an energy monitoring model looks like this:
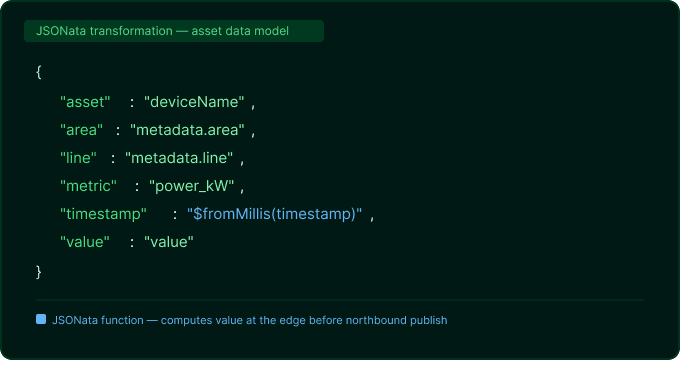
Transformations run at the edge, before data is published to any northbound integration. The result is a clean, typed, structured payload that consumers can use directly.
Schema / Hierarchy — The Data Structure
The schema defines the logical structure of the Digital Twin payload. You drag and drop static and dynamic attributes into a hierarchy—grouping them into categories like telemetry and properties, or any custom structure that matches your asset model. This hierarchy determines what the full Digital Twin JSON object looks like when it's published.
The Litmus Edge Digital Twins framework doesn't constrain you to a fixed set of model types. You can model any industrial data structure—an asset, a production line, a batch process, a quality inspection workflow, a fleet of AGVs, a utility metering system, or a custom use-case payload built for a specific analytics pipeline. If it has attributes you want to track and a structure you want to define, you can model it.
Three common starting points illustrate the range:
Asset Data Model
The most common starting point. It represents a single physical asset: a CNC machine, a robot cell, an energy monitoring device, a pump, a compressor. Static attributes carry identity (manufacturer, serial, location). Dynamic attributes carry the asset's live signals. An energy monitoring asset model, for example, might publish power, energyUsed, cost, energyRate, season, and shift as a single structured payload—with cost computed on the fly from the raw power and rate data.
Process Data Model
Process models represent a production line, a batch process, or a multi-step workflow rather than a single asset. Dynamic attributes track throughput, cycle time, yield, batch ID, or process state. Static attributes identify the line, the plant, and the product being run. This model type is well-suited for OEE calculations, where availability, performance, and quality metrics need to be aggregated across multiple assets on the same line.
Use-Case Data Model
Use-case models are purpose-built for a specific analytical outcome. A predictive maintenance model might combine vibration amplitude, bearing temperature, and runtime hours from several asset models into a single structured payload designed for an ML inference pipeline. The model's schema matches exactly what the downstream model expects—not what the PLC happens to publish.
These three are examples, not limits. In practice, teams build models that reflect how their operations are actually structured—whether that's a utility metering model aggregating data across 50 sub-meters, a quality model capturing inspection outcomes at each stage of a production run, or a multi-machine cell model grouping related assets under a shared process hierarchy. The flexibility is intentional: the model you build should reflect your operational reality, not a generic template.
One of the most operationally significant capabilities in Litmus Edge is the relationship between models and instances, managed at scale through Litmus Edge Manager.
You create a Data Model once—define its attributes, transformations, and schema. You then deploy that model from Litmus Edge Manager to any number of Litmus Edge nodes across your facilities. Each node creates instances of the model, mapping the model's dynamic attributes to the actual tag topics available on that site's connected devices.
Static attributes are customized per instance: the Toronto plant gets plant: Toronto, the Detroit plant gets plant: Detroit. The model structure is identical. The identity and data source differ.
Litmus Edge Manager also provides centralized version control for models. When a model is updated—a new attribute added, a transformation refined—you can push that update to all deployed instances from a single location, without touching each edge node individually. Model versioning ensures you always know which version of the structure each site is running.
Once an instance is running, Litmus Edge publishes the Digital Twin payload to its internal message broker at a configurable interval. From there, the structured payload is available to any integration target:
Litmus Unify
The payload is published to the Unified Namespace (UNS) as a governed, real-time topic, available to any OT-IT subscriber via MQTT pub / sub. No point-to-point integrations required.
Cloud storage and analytics platforms
Scheduled or event-driven export of structured JSON payloads, ready for ingestion without transformation.
Relational and time-series databases
Enabling the flatten hierarchy option converts nested JSON objects into single-level key-value pairs, making the payload directly insertable into SQL or InfluxDB targets.
Edge analytics and AI
The structured payload feeds directly into Litmus Edge's built-in analytics flows and any deployed AI/ML inference applications running on the same node.
The payload sent to every receiver is the same structured, contextualized object—not a raw tag value, and not a partially-mapped stream. Context is baked in at the source.
You could, in principle, build these models in a cloud transformation layer. But doing it at the edge offers advantages that matter at production scale.
Latency and local execution. Transformations and context enrichment happen before data leaves the plant. Edge analytics and Industrial AI applications get structured inputs with zero cloud round-trip time.
Bandwidth efficiency. Sending a structured, computed payload—cost: 37.90, season: winter, shift: 2—is far more efficient than sending raw tag streams and computing those values in the cloud. You reduce data volume before it crosses the network boundary.
Air-gapped and offline support. Litmus Edge runs fully offline. In air-gapped environments where cloud connectivity is unavailable or restricted, Data Models continue to operate and publish locally. No cloud dependency in the critical path.
Resilience at the source. If the connection to a cloud system drops, the edge continues collecting, contextualizing, and storing data locally. When connectivity is restored, structured payloads are available for backfill. You don't lose context during outages.
- 1.
What is the difference between a Data Model and a Digital Twin in Litmus Edge? They are the same thing. In Litmus Edge's technical language, Data Models are implemented as Digital Twins. A model defines the template (attributes, transformations, schema), and instances of that model represent specific physical assets or processes.
- 2.
Do I need Litmus Edge Manager to use Digital Twins? You can create and run Digital Twin instances directly in Litmus Edge. Litmus Edge Manager adds centralized model management, version control, and the ability to deploy and update models across multiple Litmus Edge instances at scale. Digital Twins requires a Scale or Growth Litmus license.
- 3.
Can I import and export Data Models across sites? Yes. Litmus Edge supports exporting a full model—attributes, transformations, hierarchy, and schema—as a JSON file, and importing it into any other Litmus Edge instance. This makes it straightforward to replicate a validated model across plants without manual reconfiguration.
- 4.
How does a Digital Twin payload get sent to a cloud analytics platform? Each instance publishes its structured payload to the internal message broker. You configure a northbound integration in Litmus Edge's Data Integration module—pointing at your cloud storage, message broker, or analytics endpoint—and the structured Digital Twin payload is delivered on your chosen schedule or trigger.
The gap between what shop floor assets generate and what analytics systems need is a context problem—and context belongs at the source. Litmus Edge Data Models give you the tools to define that structure once, deploy it across every site, and send every downstream system a payload it can use immediately.
Explore the Digital Twins documentation on docs.litmus.io to walk through model creation, instance configuration, and transformation setup. Ready to see it in your environment?