
Litmus Edge sits on a critical boundary in industrial architectures: it connects to OT assets & industrial IT system, normalizes and contextualizes data, runs edge analytics/AI, and reliably integrates data into enterprise systems. When those capabilities are unified in one platform, availability is no longer a “nice-to-have”—it’s a platform requirement. A disruption at the edge doesn’t just affect one flow; it can interrupt ingestion, transformation, and delivery across multiple consumers. High Availability (HA) in Litmus Edge is designed to keep that edge data foundation running by providing automatic failover from a primary node to a synchronized backup node.
High Availability (HA) in Litmus Edge provides a primary/backup node setup where the backup stays synchronized with the primary. If the primary node becomes unavailable, the backup can take over automatically, helping maintain continuity for your edge workloads and protecting key Litmus Edge configuration/state.
Litmus Edge HA is also designed to operate reliably in environments with low bandwidth or uncertain connectivity, which is a practical reality across distributed industrial sites.
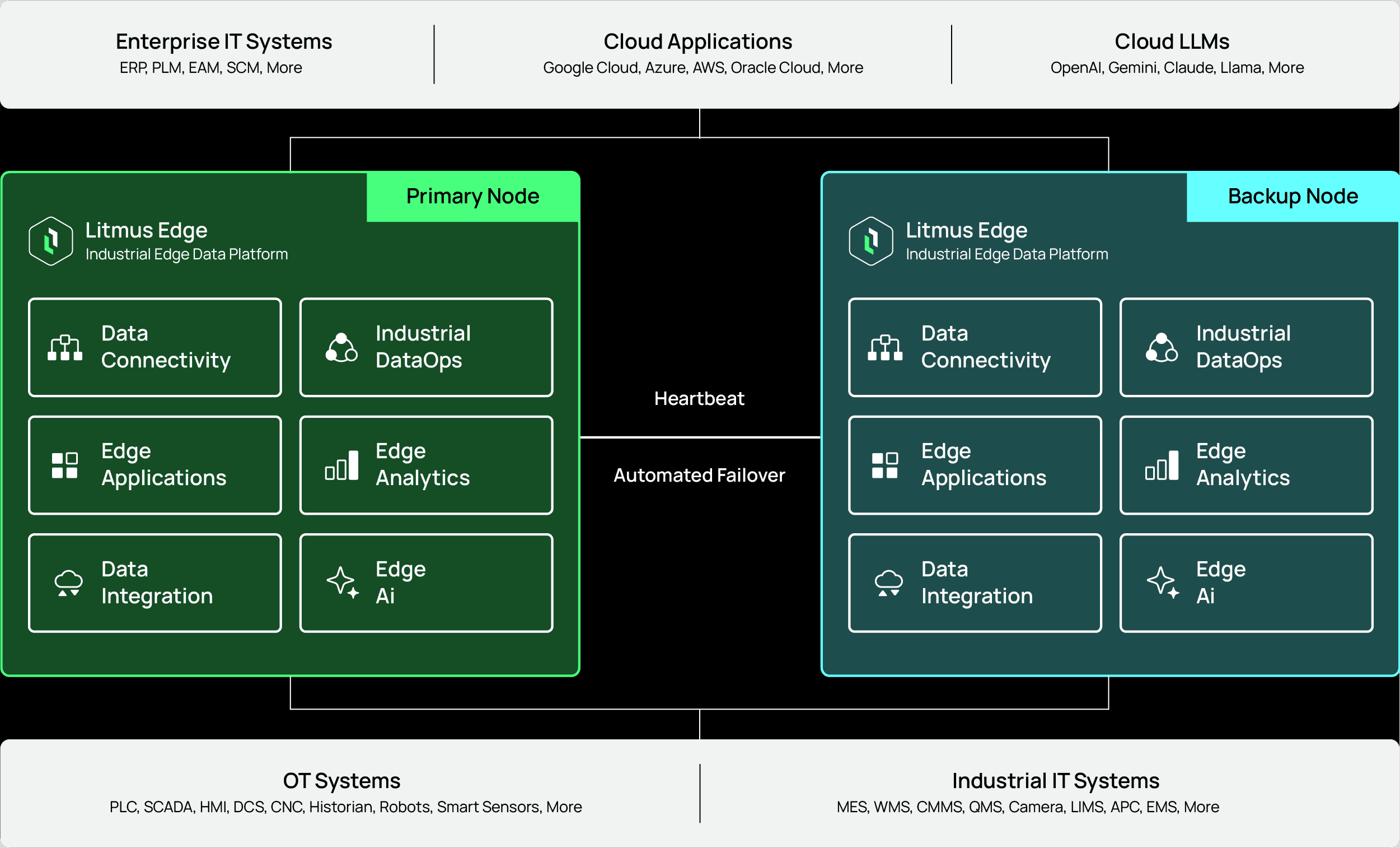
Litmus Edge HA continuously validates node health using a heartbeat mechanism and triggers failover when the system detects the primary is no longer reachable. Key mechanics include:
Primary and backup nodes continuously monitor each other via heartbeat.
Failure threshold: failover triggers after missed heartbeats.
Operational visibility: HA status and synchronization details are recorded (including heartbeat activity, roles, and rsync/sync timing), which helps teams validate readiness and troubleshoot quickly.
This design gives you a predictable detection-and-recovery model that’s easy to test in commissioning and easy to monitor in operations.
Once configured, Litmus Edge exposes practical, operator-friendly health indicators such as:
Last heartbeat sent to the backup
Last heartbeat received
Count of consecutive heartbeat failures
Peer reachability
The configured heartbeat interval and failure threshold
These signals make HA observable in real time.
As Litmus Edge is being used as the data foundation for edge data: connect → contextualize → analyse → integrate; High Availability is the most valuable feature as HA directly reduces risk and operational friction:
Fewer data gaps: minimizes breaks in dashboards, KPIs, traceability, and downstream analytics when a node is disrupted
More predictable maintenance: enables planned work (patching, upgrades, hardware swaps) with far less operational exposure
Lower recovery effort: automated failover reduces manual intervention, while logs and sync details accelerate troubleshooting
Better continuity for downstream systems: reduces the chance of missed windows for integrations that expect steady, continuous edge delivery
High Availability isn’t a standalone checkbox—it reinforces the core reasons teams standardize on Litmus in the first place:
One platform: When connectivity, integration, analytics, and edge AI are unified, HA protects that unified data foundation—so uptime applies to the whole edge stack, not just one component.
Fast to deploy: HA is configured directly in-product with a clear primary/backup flow (backup token + hostname), supporting rapid rollout patterns at the edge.
Massive scale: As edge pipelines expand across assets, lines, and sites, HA helps make reliability repeatable and standardized—critical for enterprise rollouts.
Easy to manage: Heartbeat health, peer reachability, and sync status provide day-to-day operational visibility without custom tooling.
Yes. Litmus Edge HA supports automatic failover from a primary node to a synchronized backup when the primary becomes unavailable.
Yes. Litmus Edge HA is designed to remain reliable even with low bandwidth or uncertain connectivity.
High Availability is available in Litmus Edge 4.x.
Industrial teams don’t adopt an edge data platform just to “connect devices.” They adopt it to create a repeatable edge data foundation that can be rolled out broadly—site after site—without reliability degrading as complexity grows. HA supports that objective by making uptime a designed-in capability of the platform.
With HA in place, you can operationalize edge uptime in a way that’s meaningful to both engineering and the business:
Measurable continuity: heartbeat-based monitoring and clear failover thresholds turn availability into something you can validate, observe, and operationalize—not just assume.
Scalable standardization: a consistent primary/backup pattern reduces site-specific variation, which is one of the biggest hidden costs in multi-plant deployments.
Confidence in expansion: when the same platform handles connectivity, integration, and analytics, HA reduces the risk of “single-node dependency” becoming the bottleneck as you scale across assets and lines.
Stronger downstream reliability: stable edge operations improve the reliability of everything that depends on edge data—quality monitoring, OEE, energy analytics, predictive maintenance, and enterprise reporting.
In short, HA helps Litmus Edge deliver on the promise behind the platform: one foundation that’s fast to deploy, easy to manage, and ready to scale—without sacrificing uptime.
High Availability is available in Litmus Edge 4.x. Download Litmus Edge and try it for free to evaluate HA in your environment.