Industrial organizations have invested heavily in connectivity, dashboards, and AI—but still lack trust in the data. KPIs don’t always reconcile with plant-floor reality. Gaps, spikes, and inconsistencies appear without clear cause. Ownership is unclear, and dependencies are hard to trace.
Without visibility into how data is defined, structured, and used, analytics and AI initiatives stall before they scale.
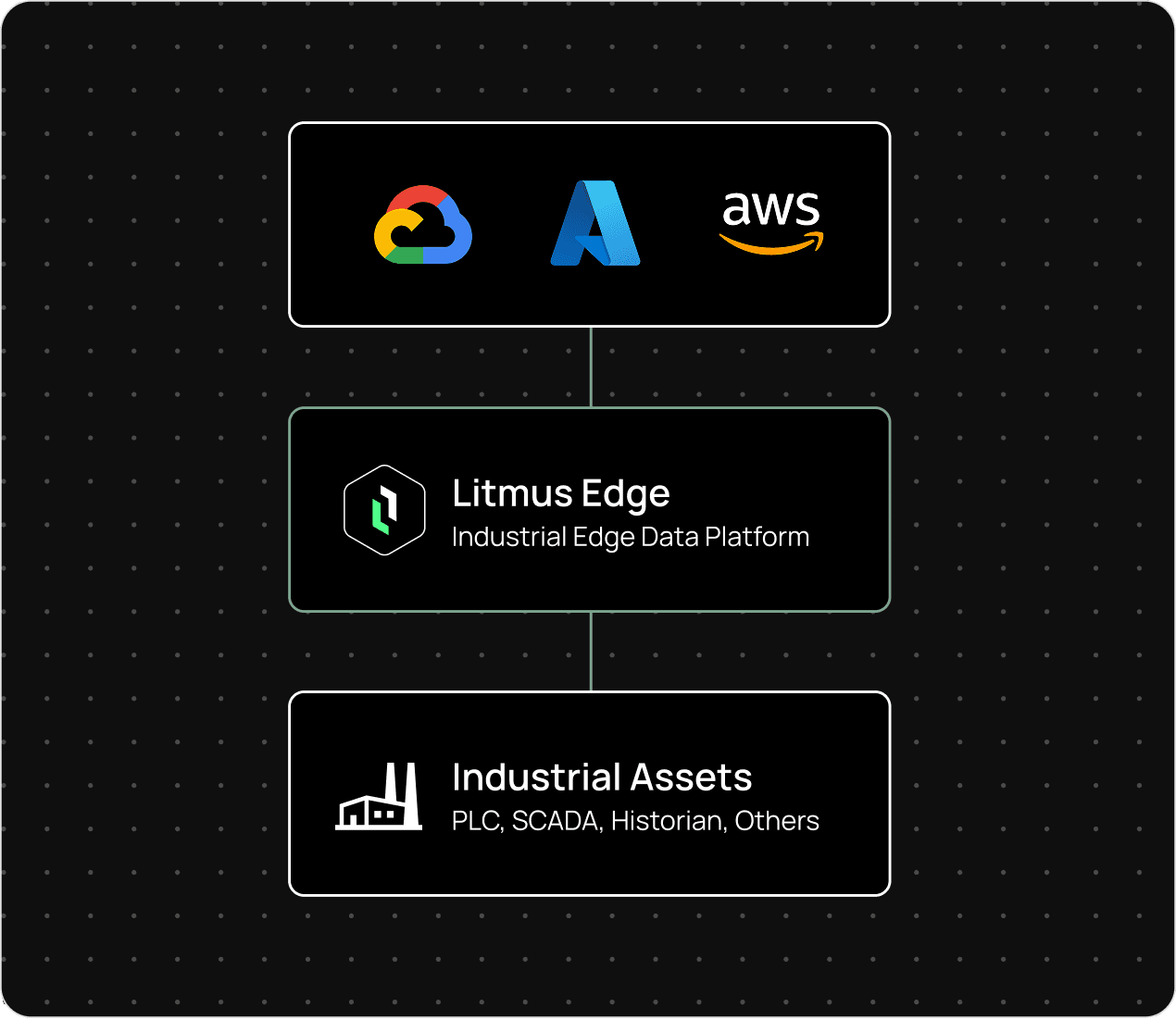
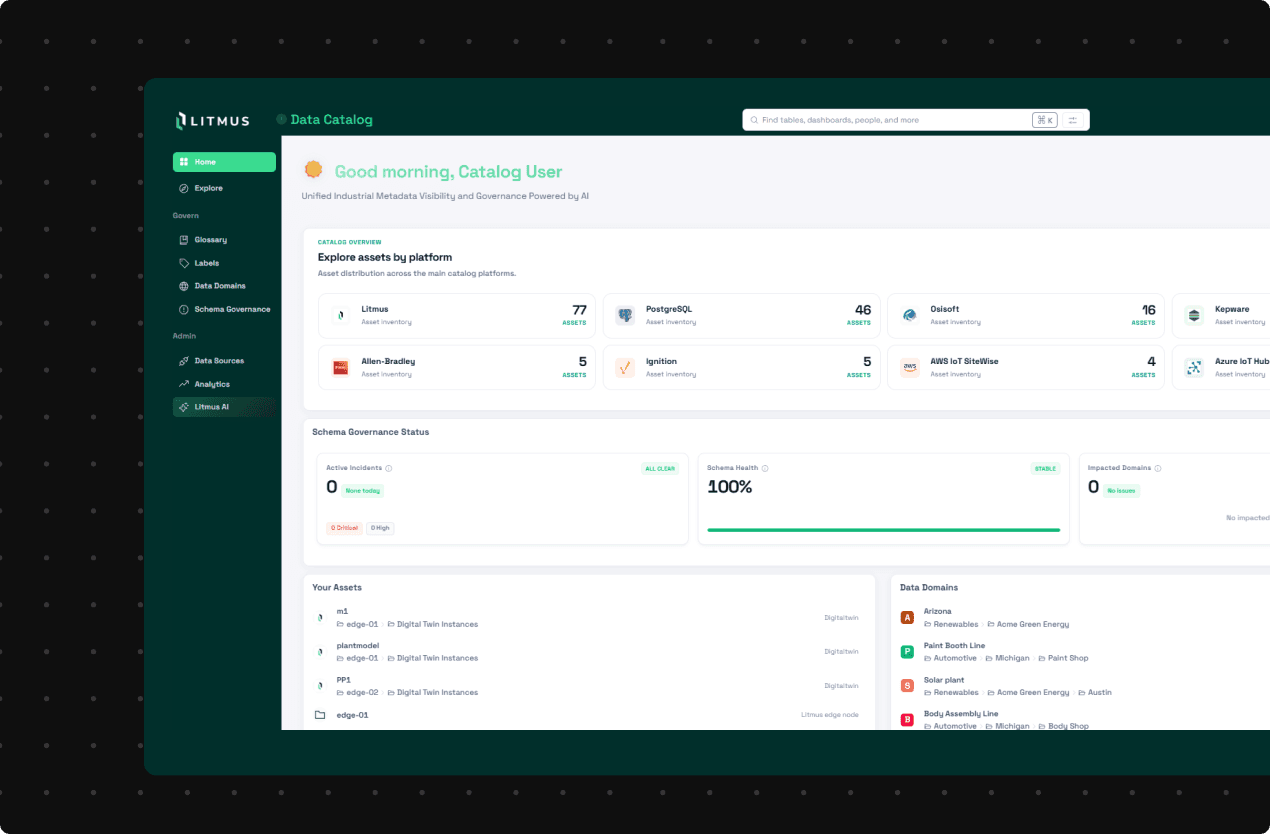
Litmus Data Catalog is the metadata and governance layer of the industrial data architecture.
While Litmus Edge collects operational data and Litmus UNS governs real-time data exchange, Data Catalog makes data interpretable—exposing lineage, standardizing terminology, and assigning ownership so it can be trusted for analytics and AI.
standardized industrial data architecture

optimized packing and volume tracking

standardized industrial data architecture

Real-time monitoring and corrective action

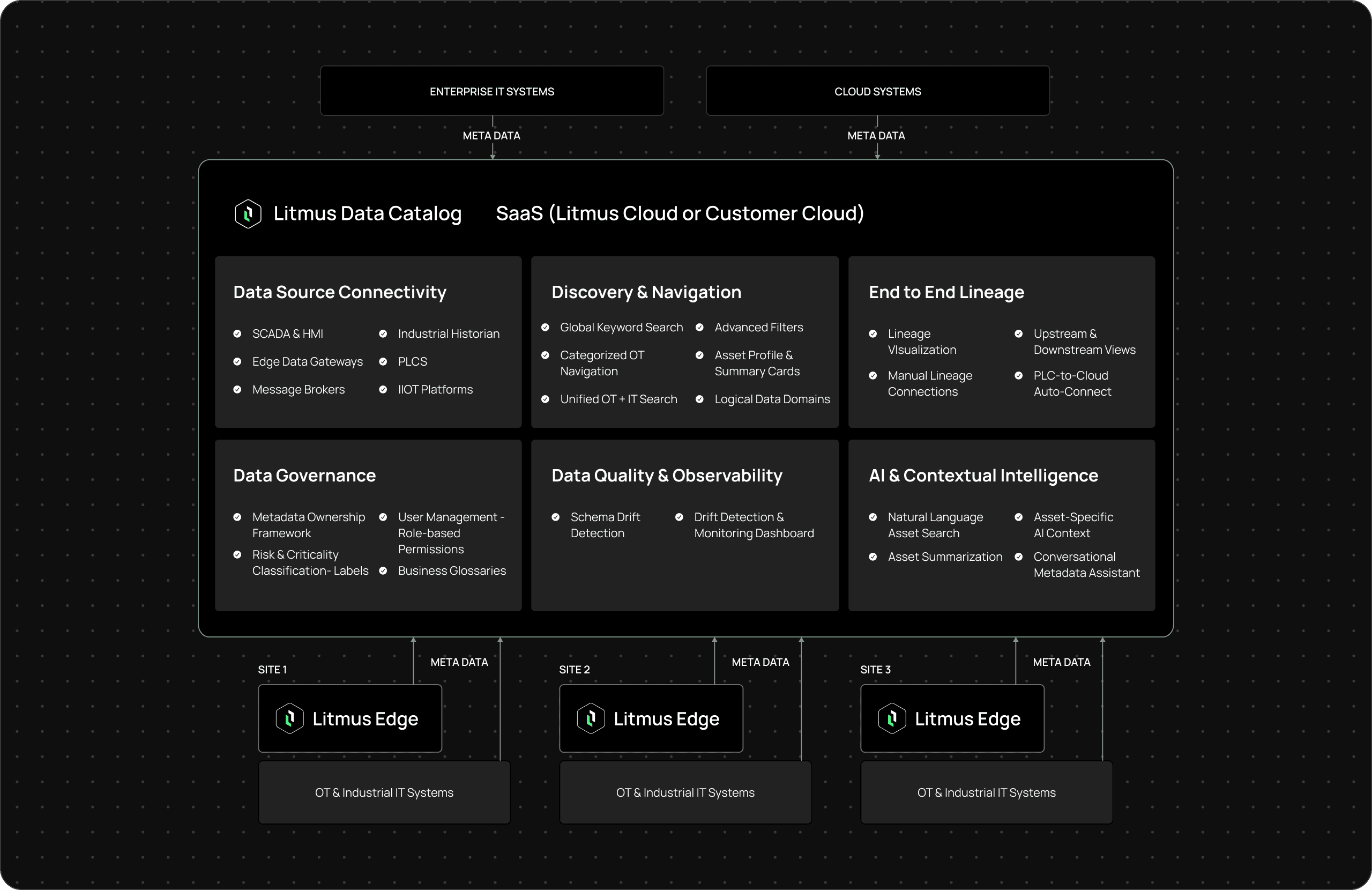
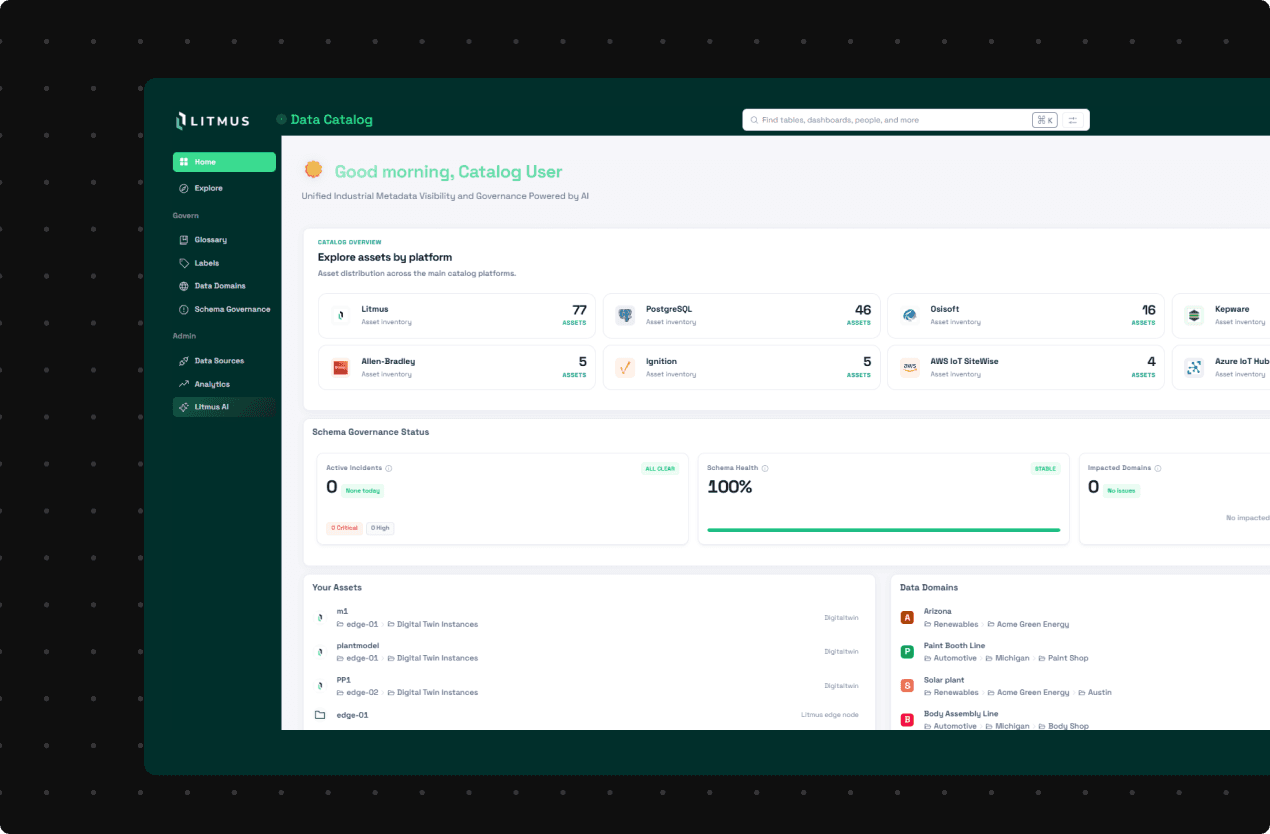
Core capabilities for industrial metadata visibility and governance.
DATA SOURCE CONNECTIVITY
Industrial data doesn’t live in one system—it’s distributed across OT and IT. Litmus Data Catalog connects metadata across PLCs, SCADA, historians, edge systems, and cloud platforms, creating a unified view of how data exists across the environment.
Key features:
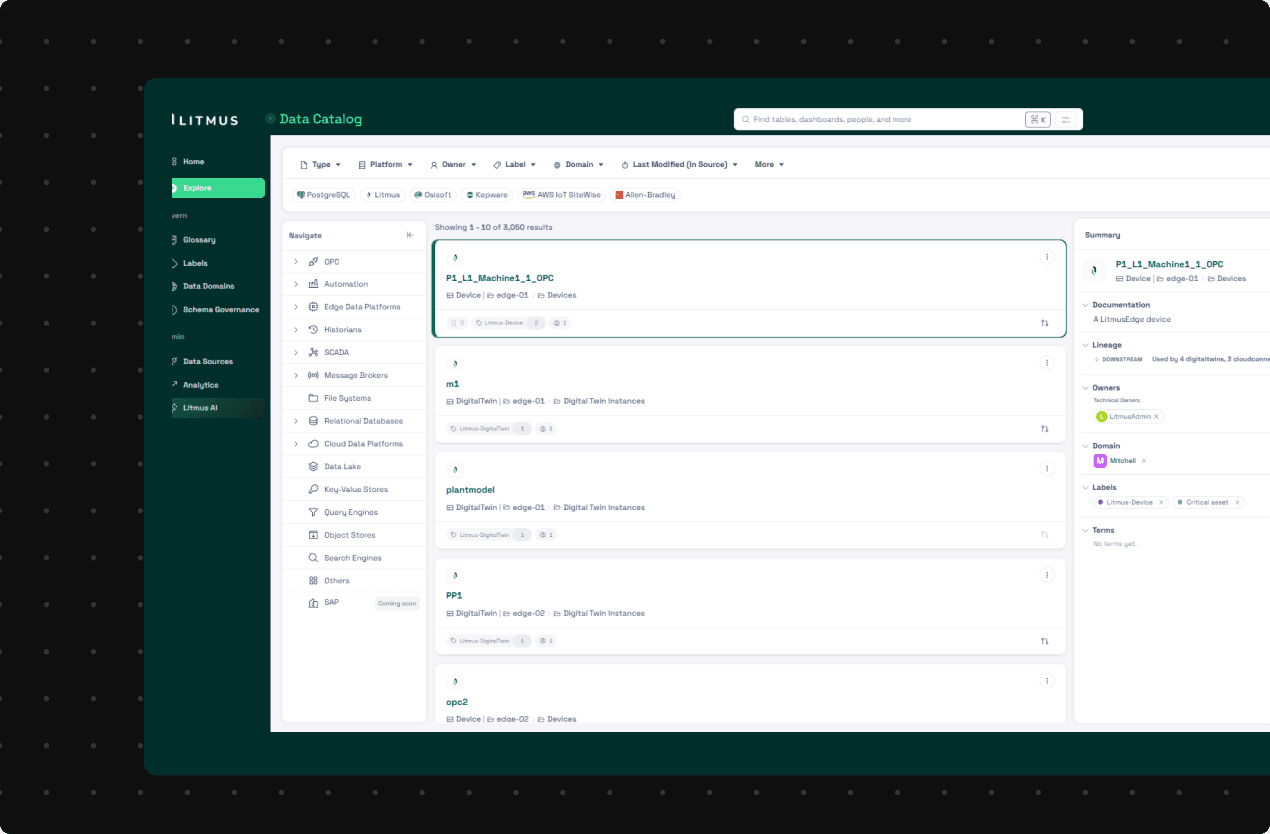
DISCOVERY & NAVIGATION
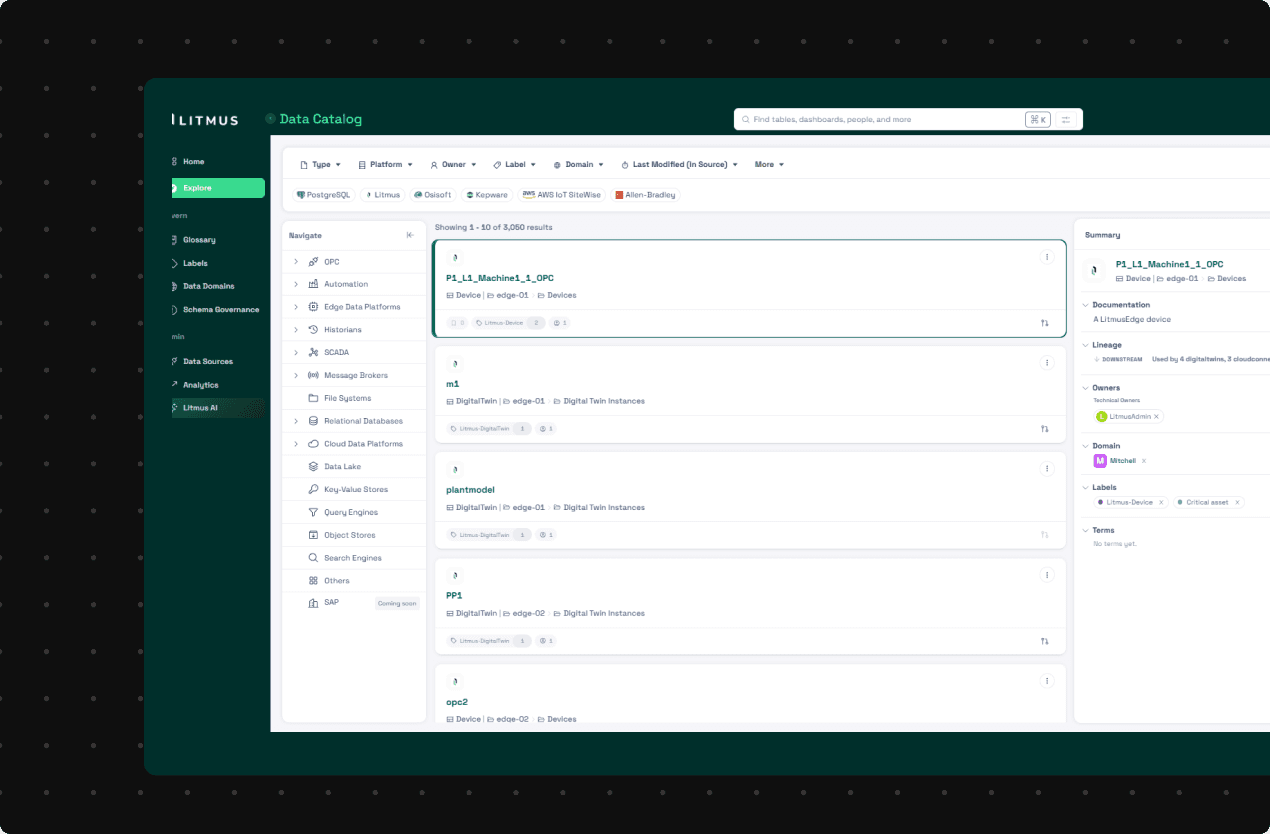
As metadata volume grows, finding the right dataset becomes a bottleneck. Litmus Data Catalog moves from flat search to structured exploration, enabling fast discovery and navigation so teams can quickly locate, understand, and use industrial data.
Key features:
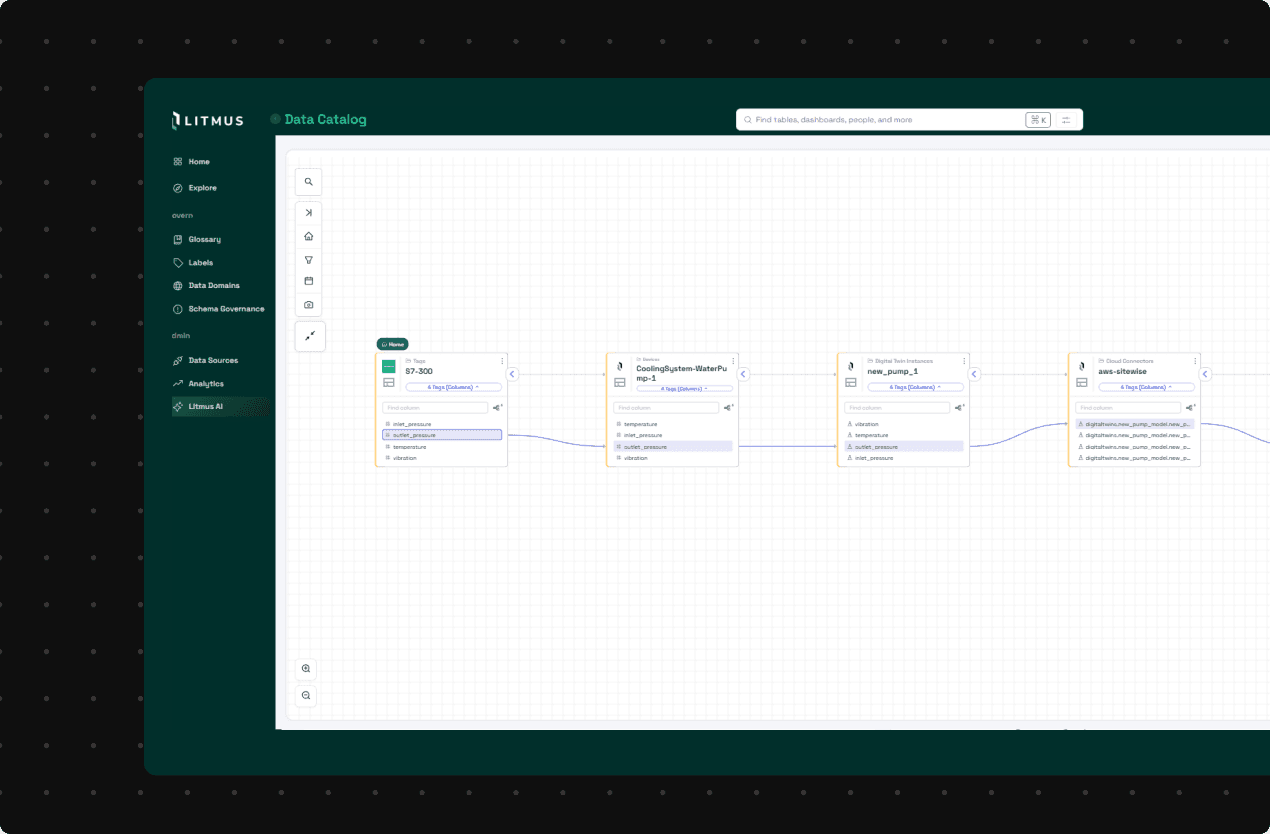
END-TO-END LINEAGE
Industrial teams need visibility into how metadata connects across systems and workflows. Litmus Data Catalog provides end-to-end lineage to trace dependencies, visualize relationships, and track metadata across OT, cloud, and enterprise environments—enabling teams to validate outputs, troubleshoot issues, and trust analytics, KPIs, and AI workflows.
Key features:
Data Governance
Metadata trust improves when governance is built-in. Litmus Data Catalog ensures data is consistently defined, owned, and governed across systems and teams.
Key features:
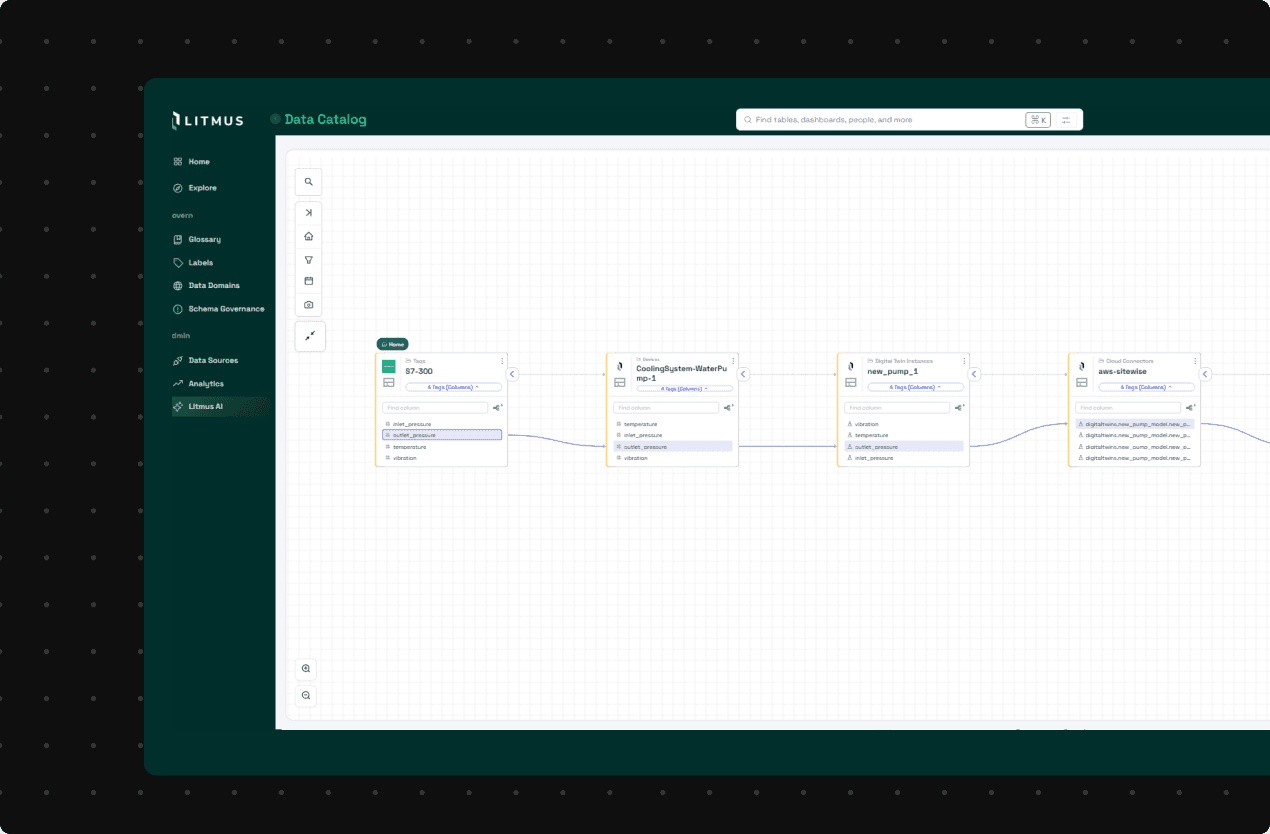
DATA QUALITY & OBSERVABILITY
Metadata quality can degrade as source systems, schemas, and pipelines evolve. Litmus Data Catalog helps teams maintain alignment across systems by detecting drift and identifying issues before they impact analytics or AI.
Key features:
AI & CONTEXTUAL INTELLIGENCE
Industrial metadata becomes more valuable when teams can interact with it in a more natural and contextual way. Litmus Data Catalog helps users move faster from raw metadata to usable, contextual understanding.
Key features:
Litmus Data Catalog creates a structured metadata operating model that improves trust, visibility, and consistency across industrial data systems.
Improve trust in analytics, KPIs, and AI outcomes
Expose lineage across systems and workflows
Enforce governance at the metadata level
Monitor drift and maintain metadata integrity
Add business and operational context with AI
Industrial teams use Litmus to standardize data architecture across plants and scale analytics and AI in production environments.
Case Study
A global brewing manufacturer deployed Litmus to replace legacy tools and standardize operational data across 95 sites. With a unified architecture built on Litmus Edge and cloud analytics, the organization streamlined data acquisition and established a consistent foundation for enterprise analytics.
Impact:

Quick answers to your industrial data questions.