Litmus Edge takes a leap forward in data analytics by integrating two powerful new processors into its platform: the File Reader and File Writer. Specifically designed to handle a myriad of file formats, they extend the platform’s capability for robust and dynamic file management. With these processors, users can smoothly transition between Litmus Edge and external systems, promising an enhanced data management experience.
A Quick Overview: Edge Data Analytics for Manufacturing Using Litmus Edge
Litmus Edge offers a comprehensive Analytics module, providing users the capability to create and manage analytics flows directly at the edge, optimizing real-time data processing and analysis. This powerful tool enables the construction of analytics flows comprising a series of interconnected processors. These processors are categorized into Input, which retrieves data from various sources like tags, topics, databases, or generators; Function, which processes the input data utilizing built-in capabilities; Statistical functions for advanced data analysis; and Output, which records the function results back to tags, topics, or databases. The module allows for intricate data manipulations through built-in Key Performance Indicators (KPIs) and a rich set of statistical functions, including calculations for mean, median, mode, standard deviation, and more, facilitating comprehensive analyses like trend forecasting, variance analysis, and performance assessments. Furthermore, Litmus Edge extends its analytics prowess by integrating machine learning models for predictions, classifications, and anomaly detection, enabling the creation and deployment of TensorFlow models with full program structures, including weights and computations. This wide array of functionalities underlines Litmus Edge's commitment to delivering a robust platform for edge-based data analytics and processing, tailored for real-time operational intelligence and decision-making.
Expanding Analytical Horizons with Flexible File Formats
The advent of the File Reader and File Writer processors by Litmus Edge broadens the horizons of data analytics with support for prevalent file formats, such as Parquet, CSV, JSON, and plain text files. This flexibility is crucial for organizations that manage diverse data types and require seamless file conversions.
Features and Benefits of the New Processors
Litmus Edge's new processors deliver a multitude of benefits to its users:
Flexible File Formats: Handle Parquet, CSV, JSON, and text files effortlessly.
Dynamic Integration: Advancement in integration with Litmus Edge’s Inject, DataHub Subscribe, and other data streams.
Data Ingestion and Export: Simplify the ingestion of data from external sources with the File Reader and utilize the File Writer for exporting data to various destinations.
Enhanced Data Management: Streamline workflows and enable efficient data transfers, boosting overall data management efficiency.
Integration with Cloud Platforms: Link with major cloud platforms like Google Cloud Platform (GCP), Amazon Web Services (AWS), Microsoft Azure, and Databricks to scale data storage and analytics.
Litmus Edge Introduces File Reader and File Writer Processors
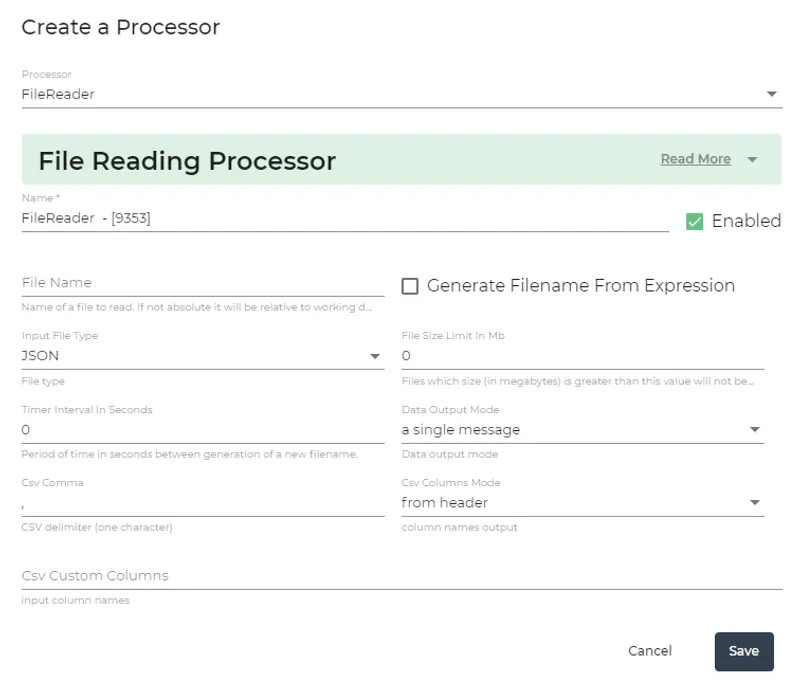
File Reader
The File Reader node within Litmus Edge Analytics stands as a robust and versatile component designed to handle an extensive range of file ingestion tasks with the ability to handle large files. Users can leverage this feature to convert various files into a string format, which can then be conveniently dispatched to messaging systems like NATS, or directly to a File Writer for subsequent operations. It boasts a dynamic approach to file paths, wherein users can specify either variable or fixed locations for the files being read, enhancing adaptability across different workflows.
File Reader
A notable feature of the File Reader is its comprehensive functionality, ensuring users have access to a full suite of data processing capabilities to cater to their unique operational needs. Its design inherently provides users with the liberty to perform file reads, adhering to the principle of allowing users to operate at the threshold of system capabilities. While this opens the doors to leveraging the full potential of the system, it is important to note that it also includes the permission for users to encounter system limitations through 'allow to fail' mechanisms, whether via the messaging system or at the Linux system level, thus promoting an environment where system robustness and user autonomy are in balanced coexistence.
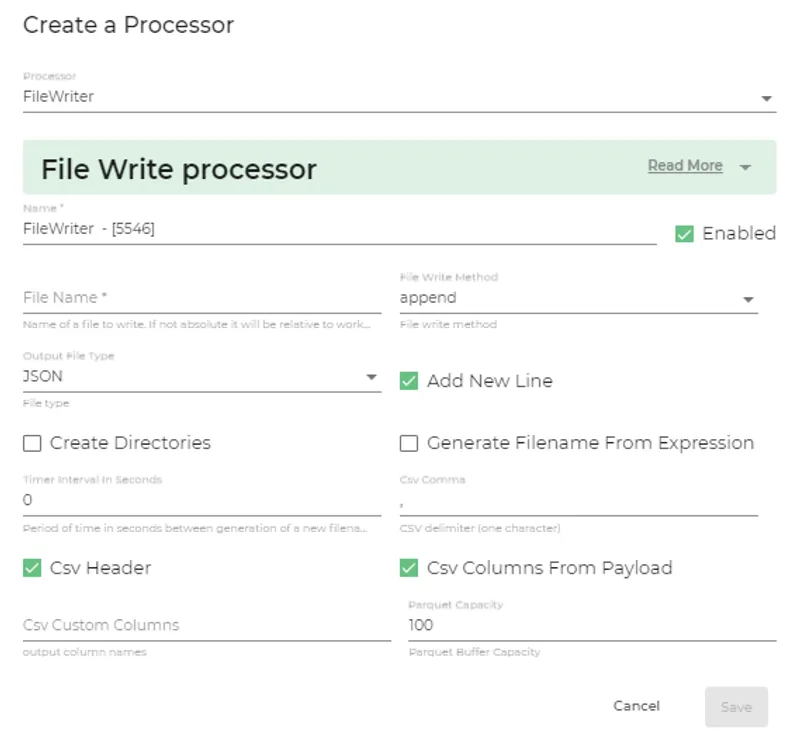
File Writer
The File Write node within Litmus Edge Analytics introduces a highly flexible and efficient method for managing and creating files directly within your analytics workflow. This feature is adept at addressing various file operation needs by enabling users to precisely define file names along with their paths for targeted data writing. Should the specified file or path not exist, the system offers a seamless option to generate the necessary file or directory, ensuring that operations proceed without interruption.
File Writer
An innovative aspect of this node is its capability to generate dynamic file names, providing a streamlined solution for users who require dynamic file management without the manual overhead of naming each file. This functionality is particularly useful in environments where data outputs are voluminous and continuous, necessitating an organized and efficient method to handle file creation.
Flexibility is further exemplified through the user's ability to choose how the data is recorded: appending to an existing file, overwriting it with new data, or opting for file deletion to manage storage effectively. Additionally, the option to append a newline character (\n) to every data payload ensures that output files are not only consistent but also easy to read and process.
Sample Use Case: Real-Time Data Analysis for Manufacturing Efficiency
Scenario
A manufacturing company is keen on monitoring production line efficiency in real-time. They collect data in various formats from machinery sensors and systems along the manufacturing line.
Challenge
The various data collected are in different file formats and need to be ingested into Litmus Edge for real-time processing and analysis. The company also needs to share this data with a cloud platform for deeper analysis and to create a backup.
Solution
With Litmus Edge's new File Reader processor, the company can ingest data immediately from the machines, regardless of the file format. Once ingested, the data can be processed and analyzed to monitor efficiency in real-time.
For deeper analysis, using the File Writer processor, the results can be exported in a suitable format to their preferred cloud platform. Here, the company can use advanced analytical tools to gain actionable insights, possibly employing AI or machine learning algorithms.
Additionally, the data can be archived for compliance with regulatory requirements, which requires data to be held in a non-editable format for a certain period.
Outcome
By leveraging the File Reader and File Writer processors, the manufacturing company achieves a streamlined workflow to enhance production efficiency, meets compliance needs, and utilizes cloud analytics for advanced insights—a testament to the versatility and power of Litmus Edge's expanded analytics capabilities.
Popular Built-in Statistical Functions for Edge Data Analytics
Litmus Edge incorporates a suite of advanced built-in statistical functions designed to empower users with sophisticated data processing and analysis capabilities. Among these, the Moving Window and Simple Window functions are pivotal for conducting rolling calculations over a specified period, which is crucial for tracking trends and patterns over time. The Anomaly Detection function stands out by enabling the identification of outliers or unforeseen events in the data, which may signify critical incidents or operational inefficiencies.
For data that exhibit a natural ebb and flow, the Rise and Fall function can detect significant variations in measurement values, differentiating between what could be considered a normal fluctuation and what might indicate a noteworthy shift in operations. The Signal Decomposition function provides a means to dismantle complex data into simpler, more analyzable components, which is essential for uncovering underlying trends and cyclic behavior.
Understanding the distribution and central tendencies in datasets is made possible by functions like the Statistical Prediction, which can harness historical data to forecast future states. To refine the data further, functions like Normalization adjust the range of values to a common scale, while Rounding ensures precision is consistent with operational requirements.
Furthermore, the Feature Extractor unlocks the potential to translate raw data into actionable insights by identifying relevant attributes or features within the data, setting the stage for more effective machine learning and predictive analytics. The Gaussian Filter function applies a smoothing technique commonly used to reduce noise and detail in statistical data, offering cleaner data inputs for subsequent analysis.
Finally, Litmus Edge provides additional utility functions such as Base Conversion, Change, and Combination Processor that furnish users with all-round capabilities to manipulate and convert data in a multitude of ways, further enhancing the robustness of their analytics workflows. Collectively, these built-in statistical functions reflect Litmus Edge’s commitment to delivering an intuitive and powerful analytics experience for users, enabling them to harvest and decipher the full value from their edge data.
Edge data analytics, as championed by Litmus Edge, is crucial in enabling businesses to process data in real time directly where it's generated. This technology reduces latency and diminishes the need for constant data backhaul to centralized cloud systems, significantly enhancing operational efficiency and responsiveness. With Litmus Edge, organizations can leverage the full power of their data on-site, leading to smarter decision-making and robust innovation in a fast-evolving digital environment.
The integration of edge computing with digital twins can help address challenges faced by manufacturers. It can reduce response time, optimize data, improve security, and lower risk.
Achieve seamless and secure remote software management for IIoT devices. Learn how Litmus Edge Manager simplifies OTA updates for IIoT devices with secure, centralized, and automated software distribution.
In today's rapidly evolving industrial landscape, the scale of the Industrial Internet of Things (IIoT) is truly remarkable. Experts expect the number of IIoT devices around the world to grow exponentially.