
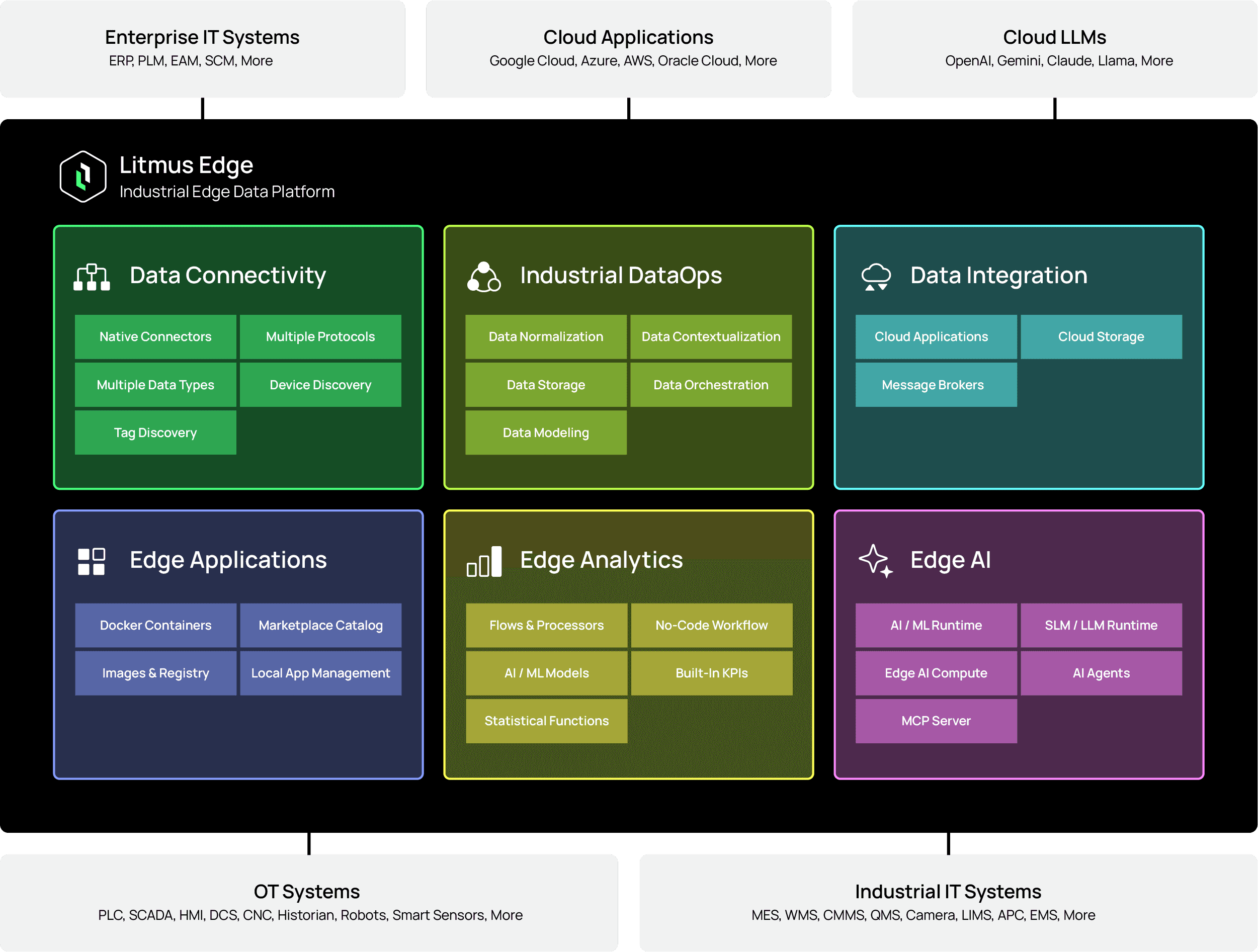
Industrial teams don’t wake up asking for “more features.” They want faster time-to-value, repeatable rollouts across sites, and fewer surprises in production. The latest Litmus Edge 4.0 update is built around that reality: it improves how you connect to data, model it, analyze it with Edge AI, operate edge apps, and keep deployments resilient—while also shipping many performance improvements and fixes.
You can now connect to more equipment types faster, find and add tags more easily, and keep performance stable as environments grow.
The new Tag Browsing experience improves the day-to-day workflow of finding and adding tags, especially when you’re onboarding lots of assets. It includes a unified search UI, persistent results, and even spreadsheet export of results for offline review and cleanup. That translates directly into:
Faster commissioning and shorter pilot cycles (less time searching, more time validating)
Cleaner handoffs between OT/controls and data teams (exportable lists)
Fewer delays when scaling from one line to a plant or multi-site rollout
Plant reality is messy: not every device fits a perfect driver pattern. The update introduces a Generic Device driver that can listen on TCP/UDP/serial, with options for secure connections, payload parsing, reading/writing, and streaming—designed to help you onboard unconventional or custom interfaces without stalling the project.
The release adds a large set of drivers and updates existing ones, plus introduces a browse registers approach designed to filter very large tag sets (200k+) with caching and improved loading behavior.
Less integration risk (no more “we can’t connect that PLC” excuses), and more confidence that the platform can handle real plant scale.
Litmus Edge data modelling feature continues to be the foundation for “data that travels well” and this update makes modelling more repeatable and scalable across equipment, lines, and sites.
You can now define parameters at the model level and use them in topic expressions for dynamic attributes. When creating instances, you can update parameter values per instance, so the same model can be reused across many assets without rebuilding logic every time. This helps customers:
Standardize naming and structure across sites (a common “data contract”)
Reduce engineering effort when rolling out to new lines/equipment
Improve downstream analytics consistency (the model stays stable even as instances vary)
Stronger transformations and subscriptions for “data that travels well”
Data modelling feature now support JSONPath and JSONata, including a playground to test transformations before applying them. You can also subscribe to specific static and dynamic attributes on unique topics, with user-defined publish intervals for static and event-based publishing for dynamic attributes. In practice, that makes it much easier to:
Produce data formats that different consumers can use (cloud services, databases, dashboards)
Avoid custom one-off parsing in every downstream system
Send “clean, consistent, contextualized” data instead of raw tag streams
Analytics is where customers often see the biggest ROI—and the latest update significantly expands what teams can do at the edge, faster and more consistently. Teams can build standardize logic across deployments, and introduce AI-driven workflows where it makes business sense.
Analytics introduces AI Model and AI Vision processor nodes, with the ability to define and manage AI model connections and choose from providers such as OpenAI, Cloudflare AI Gateway, Grok, Ollama, Google Gemini, NVIDIA, and Anthropic. You can use system/user prompts and chain multiple AI processors for more advanced workflows.
The value here isn’t “AI for AI’s sake.” It’s that you can:
Classify and summarize operational signals close to the source (faster response loops)
Add human-friendly context to alarms/events (reduce time-to-triage)
Enable vision and language-driven use cases without rebuilding your entire edge architecture
Analytics now supports user-defined variables (via UI, API, JavaScript, Tengo) and reusable parameters—so teams can maintain consistency in terminology and update values once instead of hunting through flows. This is one of the highest ROI changes for scaled deployments:
Fewer configuration mistakes across many flows
Faster replication of analytics patterns across lines/sites
Easier governance (changes are deliberate and traceable)
The update adds multiple processors including a rate limiter, JavaScript function processor, SPC charts with statistical calculations, JSONata processor, and an image preview processor. It also expands file handling: FileWriter supports user-defined output columns for Parquet, and FileReader/FileWriter support CSV/Parquet with improved usability.
For customers, these aren’t “more nodes.” They reduce the time from idea → deployed insight:
Rate limiting helps protect downstream systems and stabilize data pipelines
SPC and transformations help convert raw measurements into quality and process insights
Better file handling supports edge-to-cloud workflows and auditability
A dedicated PLC uptime/downtime tracker processor enables tracking downtime periods based on PLC values—directly supporting OEE-style KPI monitoring and faster root cause workflows.
Teams can now find, deploy, update, and troubleshoot edge applications in Litmus Edge more efficiently—without risking disruptions.
Applications add improved Marketplace filtering (category + sorting), richer metadata visibility, improved sync controls (view last sync time, sync specific catalogs), and a “Degraded” status to quickly spot containers that have exited while an app is still “running.” That’s operational value you feel immediately:
Less time hunting for the right app and version
Faster identification of “it’s running, but it’s not healthy”
Cleaner marketplace management across teams and sites
Marketplace updates now support keeping the old version active until the new one is fully downloaded, helping reduce downtime risk during upgrades. Permissions are also more granular (create/update/delete settings for “Modify”), enabling tighter governance in shared environments.
This matters when edge becomes enterprise-scale:
Lower operational risk during application updates
Clearer separation of duties between teams (operators vs administrators)
More confidence running production workloads at the edge
The latest Litmus Edge v4.x introduces High Availability capabilities using a primary/backup approach, with role/status indicators and safeguards designed to prevent split-brain scenarios. This supports continuity for edge deployments that are in the production critical path.
For customers, this means fewer “single point of failure” concerns when Litmus Edge is in the production critical path—supporting higher uptime expectations without forcing a redesign of your architecture.
Beyond the major updates above, the latest v4.x release includes broad improvements and fixes:
Data Connectivity performance and stability improvements for large environments, driver logging upgrades, better browsing responsiveness, and many driver enhancements (including OPC UA client advanced improvements, Modbus improvements, MSSQL performance improvements, and more).
Integration improvements for throughput/resource usage, persistent storage controls, template-driven scalability, subscription management at very high counts, improved connector error handling, and security options like OAuth 2.0 for REST connectors.
System improvements including unified structured logging across components, HTTP proxy support for device management/auth/licensing, label management for edge instances, improved template import/export and backup/restore robustness, and operational UX improvements (plus a TUI factory reset option when the web UI is unavailable).
If you’re evaluating edge platforms, thinking to upgrade it or scaling from pilot to production—the latest Litmus Edge 4.0 update is designed to remove the common blockers:
Connectivity that keeps up with plant reality (faster tag discovery + broader drivers + “connect to anything” options)
Data modelling that standardizes and scales (parameters + better transformations + smarter subscriptions)
Analytics that accelerates action—including Edge AI (AI nodes, variables/parameters, new processors, KPI-aligned tracking)
Edge apps that are easier to run in production (governance, safer updates, degraded status, better marketplace controls)
Resilience for critical operations (High Availability capabilities)
The biggest improvements are across data connectivity (tag browsing, drivers, and scalability), data modeling (more reusable Digital Twin patterns and transformations), analytics (Edge AI and workflow improvements), edge apps (Marketplace operations and safer updates), and high availability for resilience.
Yes, even without AI use cases, customers benefit from faster onboarding, improved scalability, better modelling/transformations, stronger application operations, and reliability improvements. Edge AI enhancements are additive—use them when they fit a real business workflow.
It reduces common scale blockers: faster tag discovery, improved large-environment performance, reusable data models via parameters, analytics standardization via variables/parameters, and more manageable edge app operations.
In Litmus Edge, data modelling is driven through Digital Twins—creating structured, contextual representations of assets and their attributes so downstream analytics and integrations can consume consistent, reusable data rather than raw tags.
The complete set of improvements and resolved issues is listed in the Litmus Edge release notes: https://docs.litmus.io/litmusedge/litmusedge404 or log in to Central Portal to view: https://portal.litmus.io/downloads