Industrial data architectures get harder to manage as sites, lines, and systems multiply. What starts as a few local edge deployments often turns into a patchwork of one-off integrations, duplicated configurations, and brittle data paths between OT, DMZ, and IT environments. Litmus Edge Cascading addresses that challenge by enabling secure, topic-based data streaming between Litmus Edge instances. Instead of treating each edge node as an isolated deployment, manufacturers can build a structured multi-edge architecture that moves contextualized operational data across machine, plant, enterprise, and cloud layers in a more controlled way. The outcome is a cleaner way to aggregate industrial data, preserve network segmentation, and support enterprise analytics, Unified Namespace strategies, and Industrial AI.
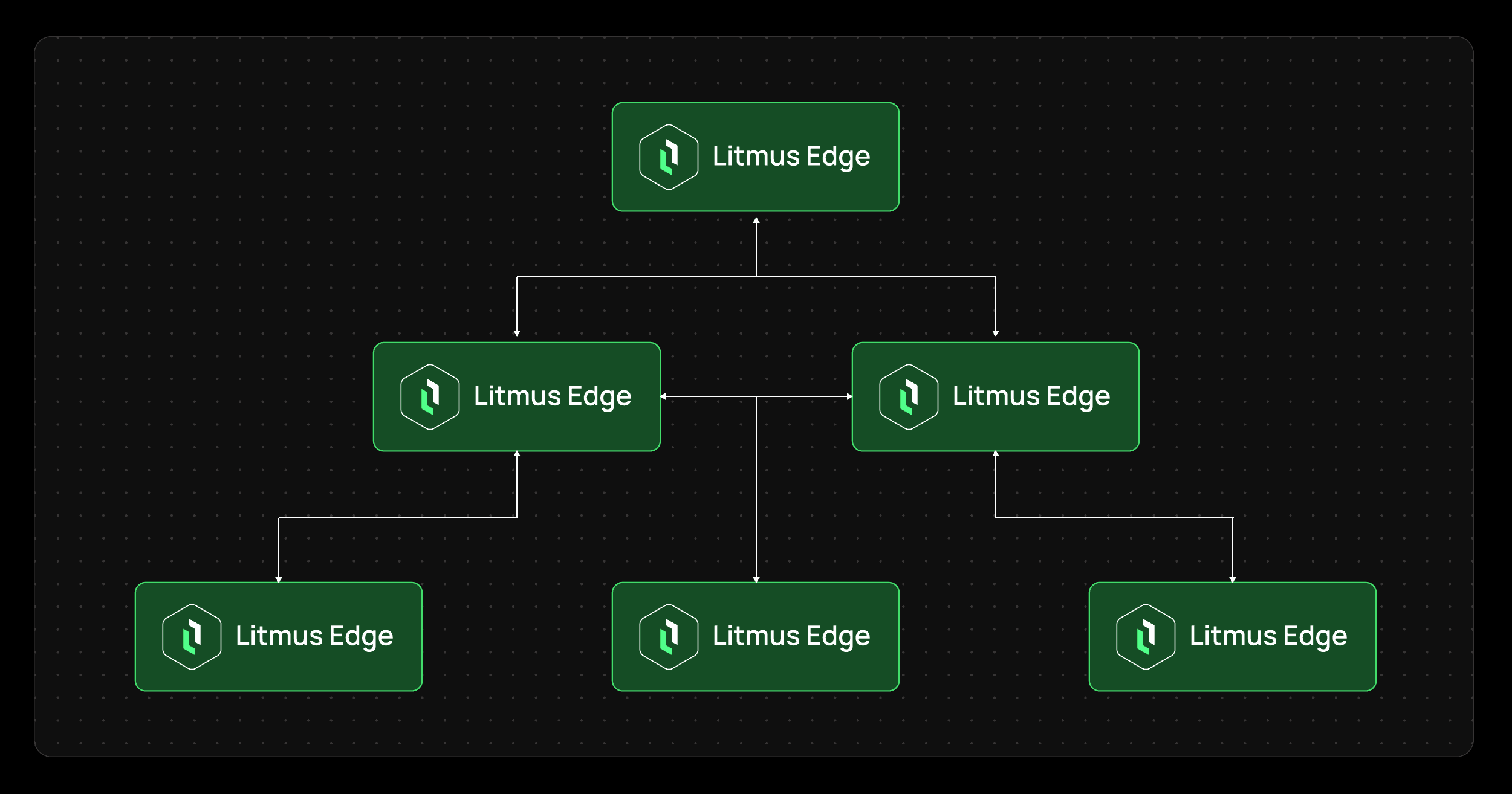
Litmus Edge Cascading allows one Litmus Edge instance to stream data to another using hub, spoke, or hybrid architectures. This gives manufacturers a practical way to move data through layered industrial environments. A machine- or line-level edge can collect data locally, a plant-level edge can aggregate and process it, and an enterprise-facing edge can forward curated streams to cloud, IT, or downstream consumers. Instead of building separate integrations for every path, Edge Cascading creates a more scalable model for edge-to-edge data movement.
It helps teams:
stream data securely between Litmus Edge instances
filter and forward only the right topics
aggregate data across lines, plants, and sites
align deployments to ISA-95-style architectures
simplify OT-to-IT data distribution
Industrial environments are not flat. Data is created close to machines, but value often comes from moving it upward into plant operations, enterprise systems, cloud platforms, and AI workflows. That becomes difficult when each layer is connected through custom logic or manual integrations. As deployments expand, teams often face:
repeated connector setup between edge systems
inconsistent data flow across sites
too much raw data pushed upstream
difficulty maintaining OT, DMZ, and IT separation
weak visibility into where data came from
rising complexity as edge instances scale
Litmus Edge already provides the foundation for industrial connectivity, contextualization, local analytics, and application execution. Edge Cascading extends that value by making those deployments work together as one coordinated architecture rather than a collection of isolated nodes.
Edge Cascading supports three deployment roles. Each one maps to a different need in a distributed industrial architecture.
A hub receives data from other Litmus Edge instances. It is typically used at an aggregation point such as a plant-level layer, DMZ, or enterprise-facing environment. A hub is useful when you need to:
centralize incoming data from multiple sites or lines
consolidate data before forwarding it upstream
apply controlled permissions to shared topics
simplify plant- or enterprise-level aggregation
A spoke initiates outbound connections and streams approved topics to a hub. This is a strong fit when you need to:
send data out of OT without opening broad inbound access
move line or machine data upward securely
support outbound-only architectures
keep local collection independent while sharing selected streams
A hybrid instance acts as both hub and spoke. It receives data from lower-level instances and forwards selected data to higher-level systems. This is useful when you need to:
bridge layers across OT, DMZ, and IT
aggregate and forward plant-level data
create multi-tier industrial data architectures
support staged filtering or enrichment between layers
Together, these roles give industrial teams the flexibility to design architectures around real operational boundaries instead of forcing every deployment into the same pattern.
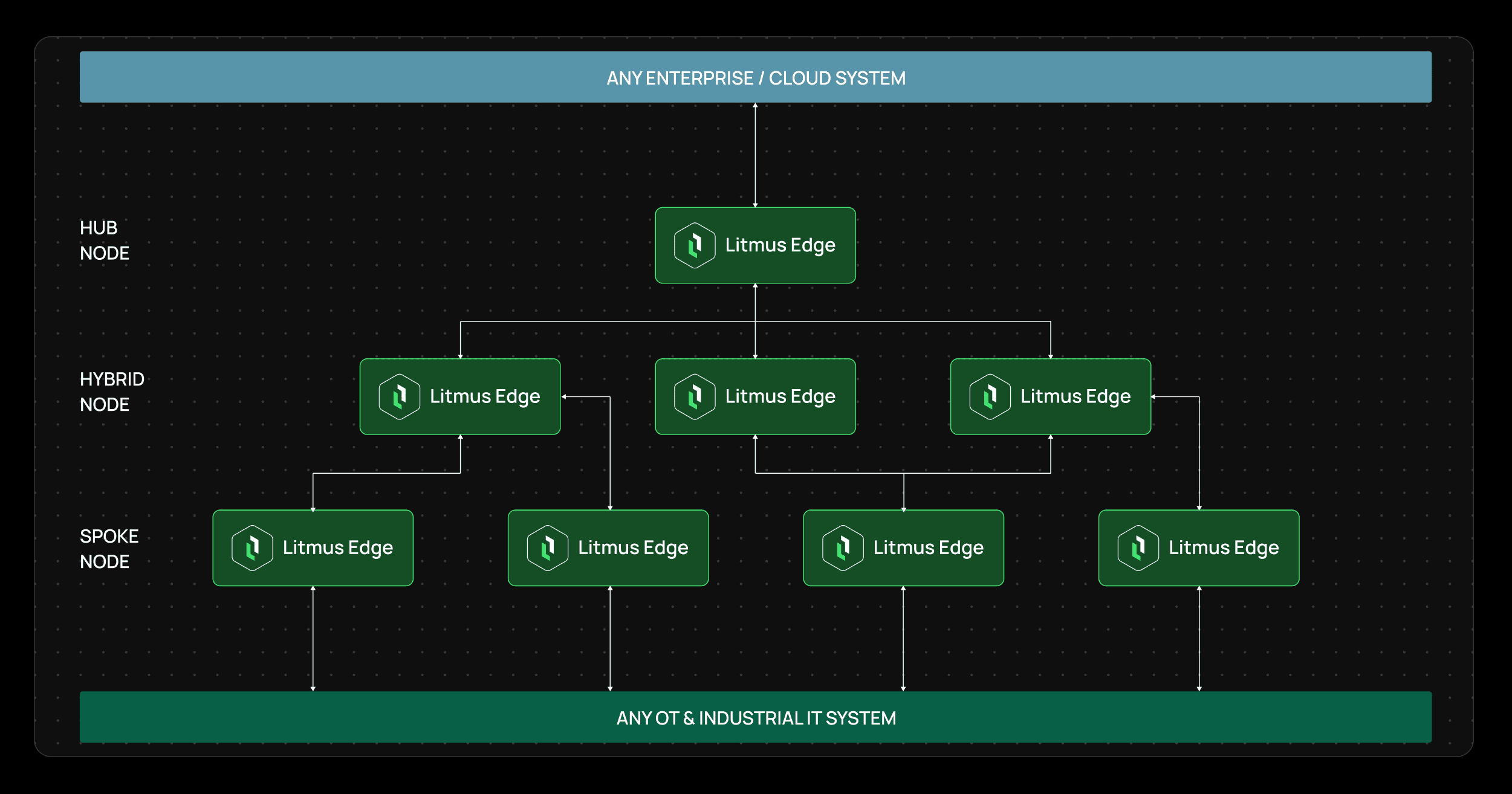
One of the biggest advantages of Litmus Edge Cascading is how well it fits layered industrial architectures. A common pattern looks like this:
Level 0-2: local spoke instances collect machine, PLC, sensor, robotics, and line data
Level 3: hybrid instances aggregate and process plant-level data
Level 4: hub instances deliver curated data to enterprise, cloud, or shared data platforms
This matters because industrial teams are not only trying to move data. They need to move it in a way that respects segmentation, security policies, and operational boundaries. Edge Cascading helps create that structure without forcing teams into fragile point-to-point connections.
Cascading is valuable not just because it moves data, but because it improves how industrial teams architect data flow at scale.
Edge Cascading supports controlled streaming between Litmus Edge instances, helping manufacturers move data across network zones without flattening segmentation. This is especially important in environments where OT, DMZ, and IT layers must remain clearly separated.
Not every consumer needs every signal. Edge Cascading makes it easier to forward only the relevant topics, which helps reduce unnecessary traffic and keeps downstream systems focused on useful, curated data. That is particularly important for multi-site environments where bandwidth and governance both matter.
As deployments expand, teams need a better way to consolidate data from multiple machines, production lines, and facilities. Edge Cascading enables that aggregation through hub-and-spoke or multi-tier designs that are easier to scale than one-off integrations.
When many edge instances publish into a higher-level layer, source organization becomes critical. Edge Cascading helps preserve source identity so downstream systems can better understand where data originated. This improves troubleshooting, analytics accuracy, and operational trust.
Industrial data often needs to move beyond the plant for analytics, reporting, or AI. Edge Cascading helps create a structured upstream path so data can be filtered, aggregated, and shared in a more governed way.
Edge Cascading is most powerful when it is viewed as part of the broader Litmus industrial data foundation.
Litmus Edge provides the underlying edge data platform for connectivity, DataOps, local analytics, applications, and AI. Edge Cascading extends that foundation so multiple Litmus Edge instances can operate as one architecture.
Litmus Edge Manager adds centralized control across distributed edge environments. As organizations scale cascading deployments, centralized governance, updates, and operational consistency become more important.
Litmus Unify (UNS) provides a governed way to structure and distribute industrial data across OT and IT. Edge Cascading complements this by helping move and aggregate data between edge layers before it is published into a broader shared namespace strategy.
Together, these capabilities help manufacturers move from isolated edge projects to a more scalable industrial data operating model.
Litmus Edge Cascading supports a range of real-world deployment models across manufacturing and industrial operations.
Each production line can run its own Litmus Edge instance, while a plant-level hub collects and consolidates approved data streams for monitoring, analytics, or upstream sharing.
Each site can publish curated data to a central hub, giving enterprise teams a more standardized way to aggregate operational visibility across plants.
A local edge can stream data into a DMZ or intermediate layer, which then forwards approved streams to enterprise or cloud systems without exposing production systems directly.
A lower-level edge can collect and pre-process data, an intermediate edge can aggregate plant context, and a higher-level system can consume curated outputs for dashboards, analytics, or AI workflows.
A spoke can stream to more than one upstream destination, supporting more resilient data-sharing strategies for critical operations.
Industrial AI depends on more than access to data. It depends on access to the right data in the right structure at the right layer of the architecture. Edge Cascading helps by making it easier to:
aggregate data from distributed sites
preserve source context as data moves upward
filter and curate what reaches enterprise systems
support staged analytics and AI architectures
maintain secure movement across segmented environments
That makes it an important architectural capability for organizations building a stronger industrial data foundation for analytics, automation, and AI.
Litmus Edge Cascading enables secure, topic-based data streaming between Litmus Edge instances using hub, spoke, or hybrid architectures.
It helps manufacturers simplify edge-to-edge data movement, aggregate data across sites and layers, and maintain more controlled industrial data architectures.
A hub receives data, a spoke sends data upstream, and a hybrid does both so it can aggregate lower-level data and forward selected streams onward.
It maps naturally to layered industrial environments where machine-level data is collected locally, aggregated at plant level, and shared upward to enterprise or cloud systems.
It supports AI readiness by creating a more structured, scalable, and secure path for contextualized industrial data to move across distributed operations.