Industrial companies have invested heavily in OT-to-IT connectivity, dashboards, historians, cloud pipelines, and AI pilots. Machines are connected. Data is moving. Analytics are running. Yet one problem continues to slow down scale: teams still struggle to find, understand, and trust the data behind the outcome. A KPI may not match what operators see on the plant floor. A dashboard trend may look wrong, but no one can quickly trace the source. An AI model may produce an insight, but teams still question whether the underlying data is complete, current, and properly contextualized. In many industrial environments, data exists everywhere, but visibility into metadata, lineage, ownership, and business meaning remains fragmented.
Manufacturers are not struggling because they lack data. They are struggling because data environments have grown faster than visibility and governance.
Across plants and enterprise operations, data now flows through PLCs, SCADA systems, historians, edge platforms, cloud systems, analytics tools, business applications, and AI workflows. But as the number of systems grows, the ability to understand and govern metadata often lags behind.

Data infrastructure exists and dashboards are operational, but confidence in the underlying data foundation remains fragile. Without a strong metadata layer, industrial teams spend too much time asking basic questions such as:
Where did this data come from?
How does it flow across systems?
What does this KPI actually mean?
Who owns this asset?
What downstream systems are affected if something changes?
Can this data be trusted for analytics, reporting, or AI?
Litmus Data Catalog is built to answer those questions faster and with more confidence.
That is why Litmus is launching Litmus Data Catalog, a new industrial metadata visibility and governance solution designed to help manufacturers make industrial data easier to find, trust, and use. It gives industrial teams a centralized way to discover metadata assets, trace lineage, standardize terminology, classify critical assets, enrich context with AI, and build stronger governance across OT and IT environments.
This expands the Litmus platform story from industrial connectivity and real-time data movement into metadata trust, explainability, and governance. It helps manufacturers move beyond simply transporting data and toward building a more structured, searchable, and trusted industrial data foundation.
Litmus Data Catalog is a centralized industrial metadata SaaS platform powered by AI. It automatically discovers and documents metadata across the manufacturing landscape and creates a unified metadata layer across OT and IT systems. Instead of focusing only on moving industrial data from one system to another, Litmus Data Catalog helps teams understand the metadata that defines how that data is used across analytics, KPIs, reporting, and AI.
Litmus Data Catalog is an important new part of the broader Litmus story. It fits naturally with Litmus Edge, Litmus Edge Manager, and Litmus Unify to create a more complete industrial data foundation.
Litmus Edge connects machines and industrial systems, standardizes OT data, contextualizes information, runs applications and analytics at the edge, and integrates trusted data with cloud and enterprise systems. It is the operational data foundation at the source.
Litmus Edge Manager provides centralized control across distributed edge environments. It helps manufacturers onboard devices, monitor fleets, manage software updates, deploy applications, govern data models, and control AI model rollout across sites.
Litmus Unify governs real-time OT-to-IT data exchange through a structured Unified Namespace. It standardizes how industrial data is published, organized, secured, and consumed across the enterprise through a governed real-time data layer.
Litmus Data Catalog adds the metadata visibility and governance layer. It helps industrial teams discover metadata assets, understand lineage, standardize business language, assign ownership, and improve trust in the data used across analytics and AI.
Together, the products create a connected and governed operating model, this combination helps manufacturers reduce fragmentation between data creation, data movement, operational management, and enterprise level governance.
In practical terms, Litmus Data Catalog helps manufacturers:
Find datasets, tags, and topics faster
Understand where metadata originated and how it flows
Standardize KPI language and industrial terminology
Organize metadata into scalable business-aligned domains
Classify critical assets by business relevance
Enrich metadata with AI-driven context
Govern metadata quality and drift over time
The result is a stronger foundation for trusted analytics, better operational alignment, and more scalable Industrial AI.
Litmus Data Catalog is designed to solve some of the most persistent industrial data challenges.
Limited lineage visibility: Many teams can see reports and dashboards, but they cannot easily trace the path behind the result. When lineage is unclear, troubleshooting takes longer, impact analysis becomes harder, and trust in analytics declines.
Inconsistent terminology across teams: Operations, engineering, IT, and business teams often define the same metric or asset differently. That creates ambiguity in dashboards, reports, and enterprise decision-making.
Low discoverability of important data assets: As data volumes grow, valuable metadata becomes harder to find. Teams duplicate work, miss governed assets, or depend on tribal knowledge instead of a shared system of record.
Weak ownership and stewardship: When nobody clearly owns an asset, governance becomes reactive. Critical datasets may be used widely without accountability for quality, change control, or documentation.
Poor AI readiness: AI needs trustworthy, explainable, and well-governed data. If metadata lacks context, lineage, and governance, AI initiatives struggle to scale with confidence.

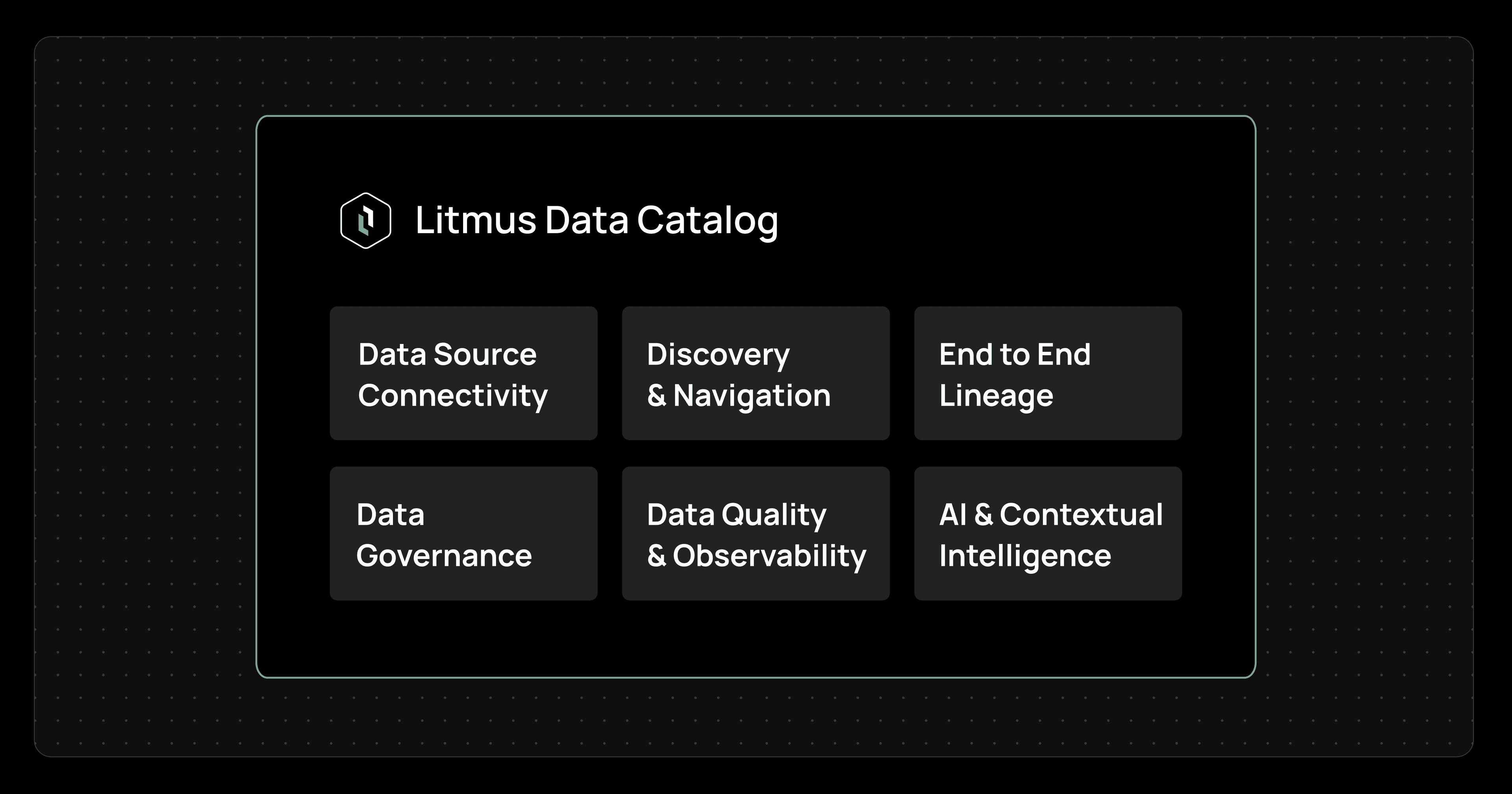
Litmus Data Catalog brings six major capabilities together in one solution.
This is the metadata ingestion layer of the catalog. It pulls metadata from systems like SCADA, historians, PLCs, brokers, and IIoT platforms so teams can see industrial data assets from different environments in one place instead of hunting across tools.
This helps users quickly find the right data asset and understand what it is. Rather than relying on tribal knowledge, teams can search by keyword, filter results, browse by category or domain, and view data asset summaries that make metadata easier to explore and interpret.
This graphical flow representation which shows how data is connected across systems from source to downstream use. It helps users understand where a dataset came from, what it depends on, and what could be affected if something changes, which is critical for troubleshooting and trust.
This is the control layer that makes metadata manageable and accountable. It defines ownership, standard terminology, permissions, and classification so teams can govern industrial data assets consistently instead of leaving them undocumented or loosely managed.
This capability helps teams monitor whether metadata is staying accurate as systems evolve. It detects schema drift and tracks metadata changes over time, so issues can be spotted early before they create confusion in analytics, reporting, or AI workflows. AI & Contextual Intelligence This adds an intelligence layer on top of the catalog so users can interact with metadata more naturally. It improves search, generates summaries, and provides contextual assistance, making it easier for both technical and business users to understand data without manually decoding every asset. Who it’s built for Litmus Data Catalog is especially relevant for industrial organizations that have already invested in digital infrastructure but still struggle with trust, explainability, and governance. This includes teams responsible for:
Industrial data and analytics teams
Industrial AI initiatives teams
Governance and compliance teams
Digital transformation program teams
Enterprise architecture teams
If a manufacturer already has connectivity, dashboards, cloud pipelines, or AI pilots in place, Litmus Data Catalog becomes the layer that helps bring more visibility and trust to the foundation behind them.
Manufacturers can register for early access to the Litmus Catalog private preview here. Litmus will also showcase the product at Hannover Messe from April 20–24. Visit the booth (Hall 16, Booth A09) to learn more.
Litmus Data Catalog is a centralized industrial metadata visibility and governance solution powered by AI. It helps manufacturers discover, understand, standardize, classify, and govern metadata across OT and IT environments.
It helps industrial teams solve common data trust problems such as unclear lineage, inconsistent KPI definitions, weak ownership, poor discoverability, and limited governance. This makes industrial data easier to trust and use for analytics, reporting, and AI.
It improves trust by exposing metadata lineage, standardizing terminology, organizing assets into domains, classifying critical metadata, enriching context with AI, and adding governance controls that reduce drift and inconsistency.
Litmus Edge connects industrial systems, contextualizes OT data, runs applications and analytics at the edge, and integrates data with cloud and enterprise systems. Litmus Data Catalog focuses on the metadata layer, making industrial data easier to discover, understand, and govern.
Industrial AI depends on trusted, explainable, and well-governed data. Litmus Data Catalog supports AI readiness by making metadata easier to find, standardize, interpret, and govern across plants, systems, and enterprise workflows.
It is well suited for industrial data teams, digital transformation leaders, OT and IT teams, governance stakeholders, and organizations building analytics or Industrial AI programs across multiple sites.