Suranjeeta Choudhury
プロダクト・マーケティング・ディレクター
未来を受け入れる:インダストリー3.0からインダストリー4.0への総合ガイド
SCADAやMES、Historian、ERP、CRM、時系列データベースなどのSOR(Systems of Records)は、インダストリー3.0の柱として役割を果たしてきた。しかし、インダストリー4.0の幕開けは激震をもたらす。

Industrial DataOps
Industry 4.0
データが新たな石油と謳われる時代において、インダストリアル・データ・オペレーション(DataOps)は、オペレーショナル・エクセレンスと競争優位のためにデータを活用しようとする企業にとって、急速に礎石となりつつある。
Suranjeeta Choudhury
プロダクト・マーケティング・ディレクター
この記事をシェアする
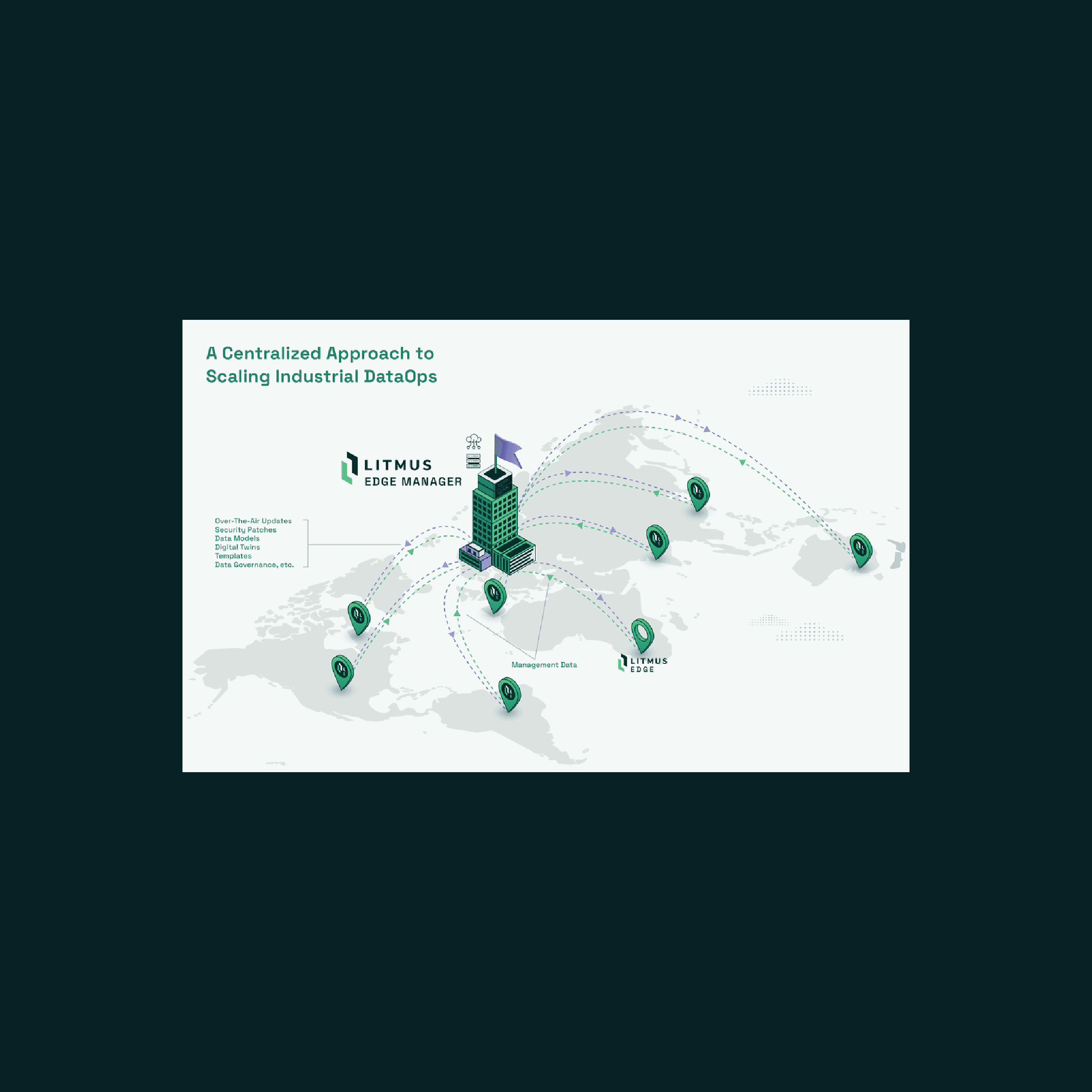
急速に変化、進化する今日のOT/ITにおいて、製造データの運用は、データを管理し、リアルタイムで事実(データ)に基づいた意思決定を推進することで、ビジネス価値を実現・獲得しようとするあらゆる試みの基礎となります。しかし、その成功は単にデータを使えるようにするだけでなく、企業や組織の全工場にわたるデータ運用を一元的で効果的、かつスケール可能にする方法で行えるかに大きく依存します。このブログでは、製造データを運用する際の拡張の課題、現在のアプローチの落とし穴、そしてデータの可能性をフルに活用することを目指す企業にとっての戦略的必須事項を説明します。
多くの企業が、データ利用の問題に関して、単にデータにアクセスし活用できるようになったから解決できたと誤解しています。ミドルウェア/製造機器との接続+データ統合+クラウド・ソリューションといったソリューションの寄せ集めが、製造データにアクセスするアプローチであることがとても多いのが現状です。このアプローチは、工場単体、あるいは少数の工場には機能的かもしれません。しかし、本当の課題は、異なる工場でさまざまなテクノロジーや機器が使用されている場合に、データパイプラインを複製できるかどうかということです。この場合、データパイプラインを管理するのに大変苦労されているはずです。
その代わりではありませんが、データパイプライン全体でデータを完全に管理する必要があります。ボトム(OTソース・データ)へのネイティブ接続からトップ(クラウド)へのネイティブ接続まで、そしてトップからボトムまで、すべて一元管理されます。これは、データソースへの直接アクセスを提供し、中間レイヤーの必要性を排除し、すべての工場オペレーションのデータパイプラインに沿った全ポイントで、所有権と一貫性を確固たるものにし、あらゆるエンタープライズ・データ・プロジェクトを大きく促進します。データパイプライン内の異種、非統合コンポーネントへの依存を回避することで、データパイプライン全体がより管理しやすく、効率的になります。
根本的な問題は、データの活用性にとどまらず、工場群のネットワーク全体にわたってデータ運用をシームレスに拡張する必要性にまでおよびます。多くの場合、新しいテクノロジーは「パイロット」として1つの工場で、あるいはせいぜい数工場で導入されます。このアプローチは、1つ、あるいは2つの工場ではうまくいくかもしれませんが、工場数が3つ、4つに増えるだけで、たちまち手に負えなくなってしまうことが多いのです。その結果、工場固有のデータ収集モデルやMLモデルのパッチワークとなり、同期や調和(オーケストレーション)はもちろんのこと、管理することもほとんど不可能になります。
多くの企業は、この「ソフトウェア・メドレー」アプローチに従って、工場ごとにデータ運用のプラットフォームを構築しようとしています。このプロセスは、工場の数が数十、数百は言うに及ばず、2つ、3つと増えるにつれて指数関数的に複雑になり、管理できなくなってしまいます。このようなDIYソリューションは、しばしば次のような課題を招きます:
一貫性のないスタンダード: 各工場は、異なる命名規則やデータ形式を使用することがあり、データの統合や分析を複雑にします
高いメンテナンスコスト:カスタムスタックは継続的なメンテナンスとアップデートを必要とし、コアビジネスからリソースを奪います
意思決定の遅延:複数の工場からのデータを集約し、標準化するために必要な時間は、重要な意思決定プロセスを遅らせる可能性があります
これらの落とし穴は非常に複雑で管理しきれなくなるだけでなく、クラウドで解決するにはコストがかかります。
効果的なデータ運用は、企業全体のスケーラビリティという目標から始めなければなりません。工場レベルでのデータを利用できるようにしデータの増強(エンリッチ化)をするのはその次なのです。データをクラウド化することも重要ですが、それが最終目標ではありません。重要なことは、データが正しく標準化され、検証され、可能な限りエッジに近いところでエンリッチ化され、すべての工場で一貫して活用できるようにすることなのです。
効率的かつ効果的に規模を拡大するために、企業は以下の確固たる戦略が必要です:
データ運用の複製と標準化:全工場で一貫したデータ管理の実施
ユースケースの伝播:ある工場における価値あるユースケースを他のすべての工場に容易に適用
アップデートの一元化:テンプレート、ファームウェアバージョン、新しいデータタグのアップデートを一元管理
敏捷性(アジリティ)の維持:データ運用を迅速に適応・管理することで、すべての工場、さらには企業全体の俊敏性と一貫性を維持
企業がデータ運用戦略を効果的に広げるためには、ML/AIモデルを容易かつ一元的に管理し、企業全体に展開できる方法を採用しなければなりません。これにはいくつかの重要なステップがあります:
一貫した企業データ戦略 - 一貫性と信頼性を確保するための共通のデータ収集基準と慣行の確立を含め、全工場でのデータ運用のための集中戦略を策定
標準化と複製 - ある工場で成功したデータ管理手法を全工場で複製できるシステムを導入し、シームレスな統合と分析のためのデータフォーマットとプロセスを標準化
俊敏なデータ管理 - 変化するビジネスニーズに対応するため、データ運用を迅速に更新・管理できるようにし続ける。この俊敏性は、競争力を維持し、新たな課題に適応するために不可欠
断片化を最小化 - データのサイロ化や非効率につながる工場固有のソリューションの開発は避ける。代わりに、全社的なデータ運用をサポートし、統合されたスケーラブルなソリューションに焦点を当てる。
データ運用を続けていく中では、製造データを一元的に管理し、その利用を拡大する能力を最優先するべきです。クリーンで、文脈化され、調和されたエンタープライズレベルのデータは、生き残るのに必要なスキルでしかありません。差別化要因になるのは、そのデータに対するニーズの変化に効果的に対応し、管理する能力です。データ・サイエンティスト、ビジネス・ユーザー、工場の運用管理者など、変化し続ける顧客のニーズに迅速に対応できなければ、終わりのないビジネスが続くことになります。つまり、データストリームを手作業で構築、再構築して、すべての工場に拡張するという終わりのないプロセスに陥ることになってしまいます。それよりも、高度にエンリッチされたオペレーション・データをリアルタイムでML/AIモデルに供給し、一元管理できるようにすることの方がはるかに重要です。これは、俊敏性を維持し、絶えず変化する環境に対応し続けるための絶対条件です。
この分野では、スケールがすべてです。すべての工場にデータ運用を拡張する能力は、今日の製造や生産環境で成功するために不可欠なのです。企業は、単純なデータの利用性を超えて、全社レベルでのデータストリームの拡張と管理の複雑さに焦点を当てるべきなのです。
一元化、標準化、俊敏性を重視した戦略的アプローチを採用することで、企業は一貫性があり、効率的かつ効果的なデータ管理ができ、真のビジネス価値と継続的な改善を促進し、競争優位性を維持することができるのです。
OT/ITの両方の状況を理解し、スケールに焦点を当て、どこにいてもンタープライズ・スケールへのロードマップを提供できるパートナーが必要です。
Litmusがどう多くのクライアントを支援しているか、具体的にお話しします。
Here’s the Japanese text with the hyperlink added:
製造データ運用をスケールさせる課題について、Litmusの社内エキスパートが現場からの洞察を披露する独占ウェビナーの録画をご覧ください。
Suranjeeta Choudhury
プロダクト・マーケティング・ディレクター
スランジータはリトマスのプロダクト・マーケティングとインダストリー・リレーションを統括している。
Suranjeeta Choudhury
プロダクト・マーケティング・ディレクター
SCADAやMES、Historian、ERP、CRM、時系列データベースなどのSOR(Systems of Records)は、インダストリー3.0の柱として役割を果たしてきた。しかし、インダストリー4.0の幕開けは激震をもたらす。
Suranjeeta Choudhury
プロダクト・マーケティング・ディレクター
統合データ戦略の主な部分を探ってみよう。なぜそれが重要なのか、そして成功している企業はどのようにしてスマートなデータ運用から価値を得ているのかについて説明する。

Vishvesh Shah
プロダクト・マネジメント・ディレクター
このブログポストでは、リトマスエッジのゼロタッチ・デプロイメント機能と、メーカーやOEMが関心を持つべき理由について説明します。
