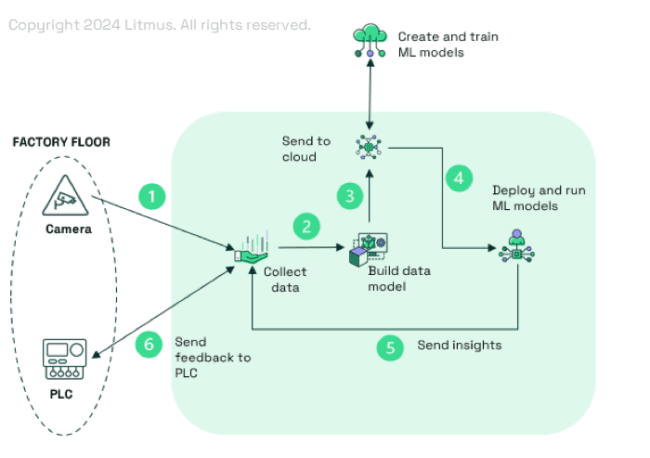
In today's fast changing and evolving OT/IT landscape, DataOps is the cornerstone of any attempt to realize and capture the business value of managing data and driving real-time, fact-based decisions. However, success relies on much more than merely unlocking data, but in doing so in a way that enables effective centralized management and scale of data operations across all an organization's plants. This white paper highlights the challenges of scaling industrial data operations, the pitfalls of current approaches, and the strategic imperatives for enterprises aiming to harness the full potential of their data.
The Misconception of Data Availability
Many enterprises operate under the misapprehension that they have solved the data availability problem simply because they can access and unlock it. A medley of solutions, including middleware/industrial connectivity + integration tools + cloud solutions are too frequently the approach to accessing operational data. This approach may be functional for an individual plant or even for a small number of plants. However, it is soon learned that the real challenge revolves around the ability to replicate the data pipeline when different plants are using varied technologies. In this case, you will struggle mightily to manage your data pipeline.
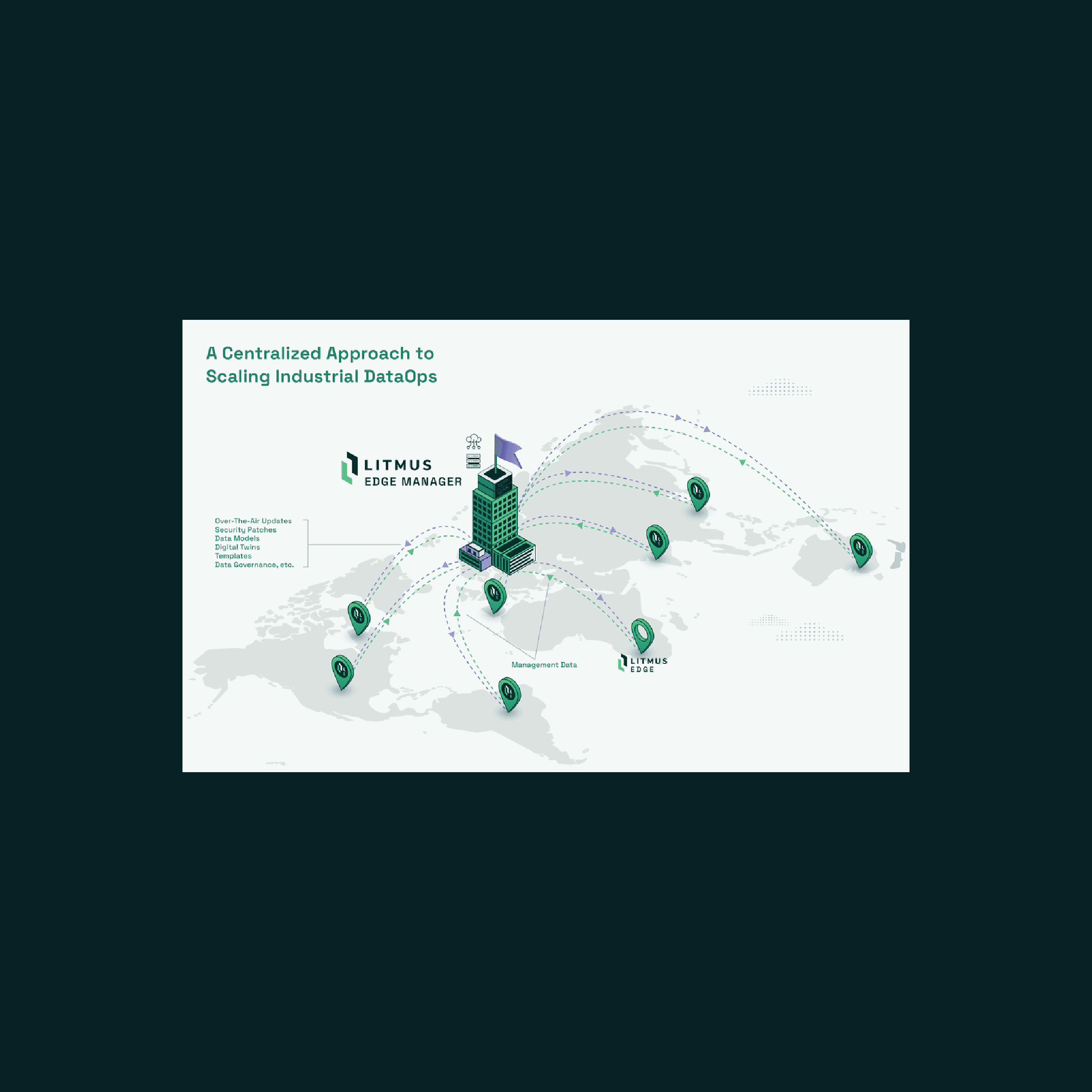
Instead, you must have total control of your data along your entire data pipeline – from native connectivity at the bottom (OT source data) all the way to native connectivity at the top (Cloud) and then from the top all the way back to bottom – all centrally administered. This significantly accelerates any enterprise data project by providing direct access to the source of the data, eliminating the need for multiple intermediary layers, and ensuring ownership and consistency at every point along your operational data pipeline, across all your plants. By avoiding reliance on disparate, non-integrated components within the data pipeline, the entire data pipeline becomes more manageable and efficient.
The Challenge of Scale
The fundamental problem extends far beyond just data availability to, in fact, the need to scale data operations seamlessly across an entire network of plants. Too often new technologies are ‘piloted’ in a single plant – or a few at most. This approach may work at one or even two plants but immediately becomes untenable as the numbers increase to even just three or four plants. The result is a patchwork of plant-specific data collection models and ML models that are nearly impossible to manage, not to mention synchronize and harmonize.
The Pitfalls of Composite Approach
Many enterprises are following this ‘software medley’ approach in attempting to build a DataOps platform for each plant. This process becomes exponentially more complex and unmanageable as the number of plants grows to even two or three, not to mention by dozens or hundreds. These DIY solutions often lead to:
Inconsistent Data Standards: Each plant may use different naming conventions and data formats, complicating data integration and analysis.
High Maintenance Costs: Custom stacks require continuous maintenance and updates, diverting resources from core business activities.
Delayed Decision-Making: The time required to aggregate and standardize data from multiple plants can delay critical decision-making processes.
These pitfalls are not only very complex and unmanageable, but extremely expensive to resolve in the Cloud.
The Journey to Effective Data Management
Effective DataOps is a journey that must begin with the goal of enterprise-wide scalability and only then should the unlocking and enriching of data at the plant level commence. While getting data to the cloud is crucial, it is not the final goal. The heavy lift is ensuring that data is correctly standardized, validated, and enriched, as close to the edge as possible, and consistently unlocked across all plants.
Key Requirements for Effective Scaling
Then, to scale efficiently and effectively, enterprises need a robust strategy that can:
Replicate and Standardize Data Operations: Implement consistent data management practices across all plants.
Propagate Use Cases: Ensure that valuable use cases in one plant can be easily transferred and applied to all others.
Centralize Updates: Manage updates for templates, firmware versions, and new data tags from a central location.
Maintain Agility: Rapidly adapt and manage data operations to maintain agility and consistency across all plants and, in fact, the entire enterprise.
Strategic Imperatives for Scaling Data Operations
For enterprises to scale their DataOps strategy effectively, they must adopt an approach that enables ML/AI models to be easily and centrally management and deployed across the entire enterprise. This involves several key steps:
1.) Consistent Enterprise Data Strategy - Develop a centralized strategy for unlocking data operations across all plants, including establishing common data collection standards and practices that ensure consistency and reliability.
2.) Standardization and Replication - Implement systems that can replicate successful data management practices from one plant across all plants, which will standardize data formats and processes for seamless integration and analysis.
3.) Agile Data Management - Maintain the ability to rapidly update and manage data operations to respond to changing business needs. This agility is essential for staying competitive and adapting to new challenges.
4.) Minimize Fragmentation - Avoid the development of plant-specific solutions that lead to data silos and inefficiencies. Instead, focus on unified, scalable solutions that support enterprise-wide data operations.
The Future of Industrial Data Operations
As we continue on our DataOps voyage, the utmost priority must be placed on the ability to centrally manage and scale the use of operational data. Clean, contextualized and harmonized enterprise level data are table stakes. It is your ability to effectively manage and react to the evolving needs for that data that is the differentiator. Without being able to rapidly react to ever changing needs of your customers – your data scientists, business users, plant operators, etc. – you will remain in a never-ending process of manually building and re-building your data stream to scale to all your plants. Instead, it is much more important to have highly enriched operation data feeding your ML/AI models real-time that you can centrally manage so you can change your data stream to adjust and reflect learnings. This is an absolute requirement if you are to remain agile and continually react to the ever-changing environment you are serving.
Conclusion
In this arena, scale is everything. The ability to scale DataOps across all plants is critical to success in the modern industrial landscape. Enterprises must move beyond simple data availability and focus on the complexities of scaling and managing your data stream on an enterprise-wide level.
By adopting a strategic approach that emphasizes centralization, standardization, and agility, companies can ensure consistent, efficient, and effective data management that drives real business value, continuous improvement, and sustains a competitive advantage.
You will need a partner who truly understands both the OT/IT landscape with a laser-focus on scale and that can meet you wherever you are on your journey and offer you a roadmap to enterprise scale.
Let’s connect so I can share with you exactly how we are helping many clients do just that.
Watch the recording of our exclusive webinar where our in-house experts share their insights from the field zooming in on the challenges of scaling Industrial DataOps.